検査と修正¶
品質検査は、一般的な翻訳ミスを発見しやすくして、翻訳が整形された状態であることを保証します。誤検出の場合は、その検査を除外にできます。
保存した翻訳が検査で不合格となった場合、すぐにユーザーに警告を表示します。
品質検査¶
Weblate では、文字列に対してさまざまな品質検査をしています。次のセクションでは、すべての検査項目について詳しく説明します。言語固有の検査もあります。誤検出が起こる場合はバグを報告してください。
翻訳時の検査¶
翻訳を変更するたびに検査をするため、翻訳者は高品質な翻訳を維持できます。
BBcode マークアップ¶
翻訳の BBcode が原文と一致しない
BBCode は、メッセージの重要な部分をボールド フォントやイタリックで強調するなどの表示を、単純なマークアップで記述します。
この検査は、それらが翻訳にも含まれていることを確認します。
注釈
BBcode を検出する方法は現在非常に単純な方法なので、この検査では誤検知が発生することがあります。
重複単語の連続¶
テキストには同じ単語が 2 回連続したものを含む:
バージョン 4.1 で追加.
翻訳に重複する単語が連続してないか検査します。通常は、翻訳ミスです。
ヒント
この検査には、誤検出を避けるための言語固有の規則が含まれています。お客様のケースで誤作動した場合はお知らせください。参照 Weblate の問題の報告。
連続スペース¶
翻訳に 2 回連続したスペースが含まれている
翻訳に連続したスペースが存在するか検査し、ほかのスペース関連の検査での誤検出を防ぎます。
原文で、スペースが連続していれば、検査で不合格になりません。スペースを意図的に連続させているからです。
書式指定文字列¶
原文から翻訳に文字列の書式指定が複製されているか検査します。翻訳で書式指定文字列を省略すると、通常は深刻な問題が発生するので、文字列の書式指定は、通常は原文と一致していなければなりません。
Weblate では、複数の言語での書式指定文字列の検査に対応しています。検査は、文字列に適切なフラグが設定されている場合にのみ自動的に有効になります(例: C 形式の 'c-format')。Gettext はこれを自動的に追加しますが、他のファイル形式や PO ファイルが xgettext で生成されていない場合は、手動で追加することが必要です。
これは、ユニットごとに行うこともできますし(参照 Additional info on source strings)、Component configuration で行うこともできます。コンポーネントごとに定義する方が簡単ですが、文字列が書式指定文字列として解釈されず、書式指定文字列の構文がすでに使用されている場合は、誤検出が発生することがあります。
ヒント
Weblate で指定した書式指定の検査ができない場合は、汎用の プレースホルダー を使用できます。
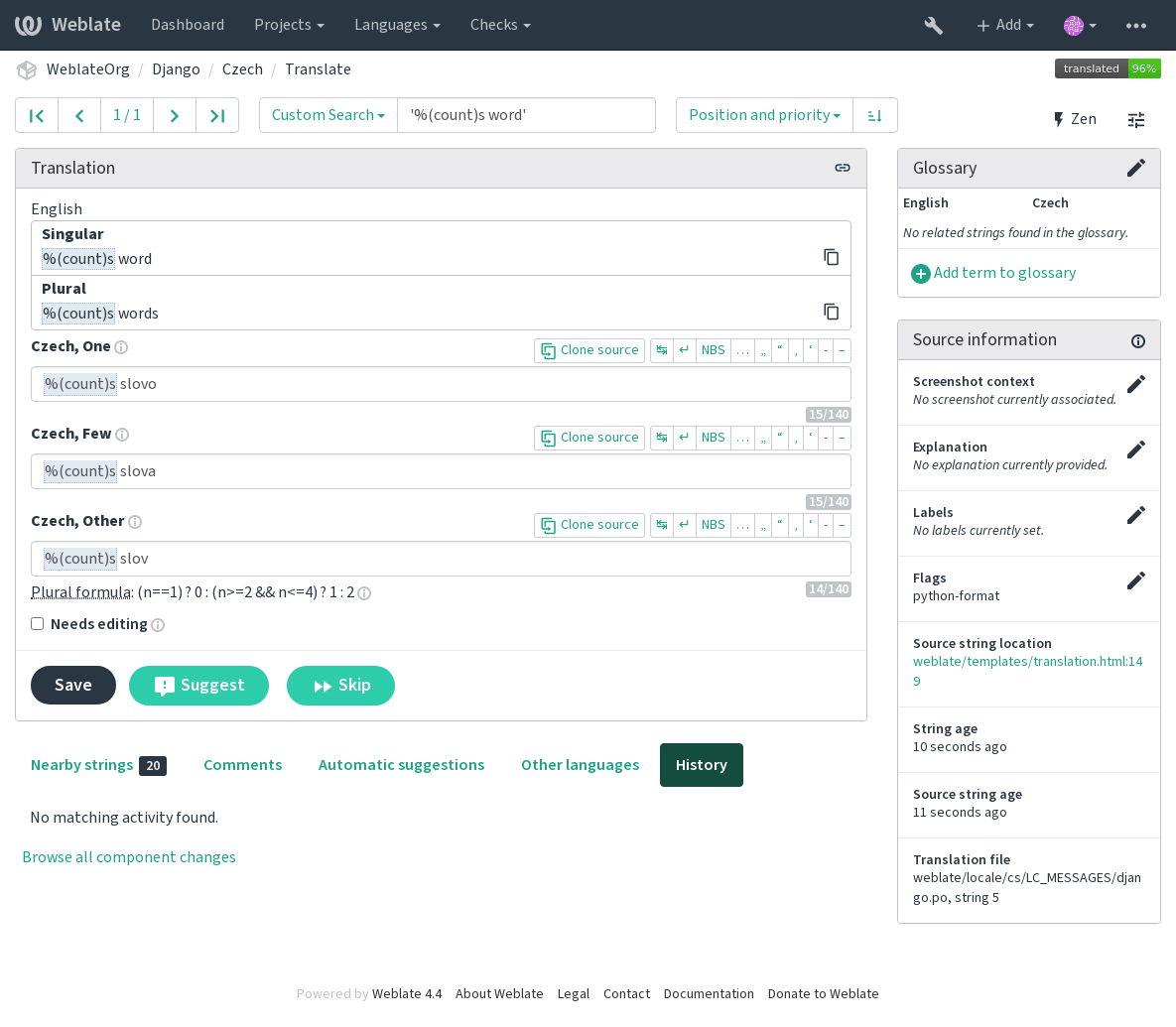
検査に加えて、書式指定文字列をハイライトで表示して、翻訳文字列に簡単に挿入できる:
AngularJS 補間文字列¶
AngularJS 補間文字列が原文と一致しない
名前付きフォーマット文字列 |
|
有効にするフラグ |
angularjs-format |
C 言語書式¶
C フォーマット文字列が原文と一致しない
単純な書式指定文字列 |
|
書式指定文字列の位置 |
|
有効にするフラグ |
c-format |
ECMAScript テンプレート リテラル¶
ECMAScript テンプレート リテラルが原文と一致しない
代入 |
|
有効にするフラグ |
es-format |
i18next 補間¶
i18next 補間が原文と一致しない
バージョン 4.0 で追加.
代入 |
|
ネスティング |
|
有効にするフラグ |
i18next-interpolation |
Java 形式¶
Java フォーマット文字列が原文と一致しない
単純な書式指定文字列 |
|
書式指定文字列の位置 |
|
有効にするフラグ |
java-format |
Java MessageFormat¶
Java メッセージ フォーマット文字列が原文と一致しない
書式指定文字列の位置 |
|
有効にするフラグ |
java-messageformat は無条件に検査を有効にします |
auto-java-messageformat 原文に書式指定文字列がある場合のみ検査を有効にします |
JavaScript 形式¶
JavaScript 書式指定文字列が原文と一致しない
単純な書式指定文字列 |
|
有効にするフラグ |
javascript-format |
パーセントのプレースホルダー¶
パーセントのプレースホルダーが原文と一致しない
バージョン 4.0 で追加.
単純な書式指定文字列 |
|
有効にするフラグ |
percent-placeholders |
Perl 形式¶
Perl 書式指定文字列が原文と一致しない
単純な書式指定文字列 |
|
書式指定文字列の位置 |
|
有効にするフラグ |
perl-format |
PHP 形式¶
PHP フォーマット文字列が原文と一致しない
単純な書式指定文字列 |
|
書式指定文字列の位置 |
|
有効にするフラグ |
php-format |
Python のブレース書式¶
Python ブレース形式文字列が原文と一致しない
単純な書式指定文字列 |
|
名前付きフォーマット文字列 |
|
有効にするフラグ |
python-brace-format |
Python 形式¶
Python形式の文字列が原文と一致しない
単純な書式指定文字列 |
|
名前付きフォーマット文字列 |
|
有効にするフラグ |
python-format |
Ruby 形式¶
Ruby 書式指定文字列が原文と一致しない
単純な書式指定文字列 |
|
書式指定文字列の位置 |
|
名前付きフォーマット文字列 |
|
名前付きテンプレート文字列 |
|
有効にするフラグ |
ruby-format |
Vue I18n 書式¶
Vue I18n 書式が原文と一致しない
名前付きフォーマット |
|
Rails i18n 書式 |
|
リンクされたロケール メッセージ |
|
有効にするフラグ |
vue-format |
一貫性の欠如¶
この原文の文字列は、このプロジェクト内で異なる翻訳が複数あるか、一部のコンポーネントには翻訳がありません。
Weblateは、プロジェクト内のすべての翻訳で同じ文字列の翻訳を検査し、一貫性のある翻訳を維持します。
プロジェクト内の 1 つの文字列の翻訳が異なる場合、検査で不合格となります。これにより、表示される検索に矛盾が生じることもあります。この文字列の他の翻訳は その他の出現箇所 タブにあります。
注釈
この検査は、文字列があるコンポーネントでは翻訳されていて、別のコンポーネントでは翻訳されていない場合にも発生します。これは、その他の出現箇所 タブの各行に表示される この翻訳を使う ボタンをクリックするだけで、一部のコンポーネントで翻訳されていない文字列を手動で処理する簡単な方法として使用できます。
自動翻訳 アドオンを使用して、別のコンポーネントですでに翻訳されている、新しく追加された文字列の翻訳を自動化できます。
Kashida 文字の使用¶
装飾用の Kashida 文字は使用しないでください
バージョン 3.5 で追加.
Kashida の装飾文字は翻訳に使用しないでください。これは Tatweel とも呼ばれます。
翻訳の最大文字数¶
翻訳文は、設定した文字数を超えてはいけない
翻訳文が使用可能なスペースに収まる文字列数かどうかを検査します。これは、翻訳文の文字列数のみの検査です。
他の検査とは違い、フラグは max-length:100 のような key:value ペアとして設定が必要です。
ヒント
この検査では文字数を確認するので、プロポーショナル フォントを使用してテキストを表示する場合は適さないかもしれません。翻訳の文字の最大サイズ 検査は、テキストの実際の表示結果を検査します。
replacements: フラグは、文字列を検査する前に配置して表示する場合にも便利です。
翻訳の文字の最大サイズ¶
表示した翻訳のテキストは、設定した文字サイズを超えてはいけない
バージョン 3.7 で追加.
表示した翻訳のテキストは、設定した文字サイズを超えないようにしてください。行折り返しでテキストを表示し、設定した境界に収まるかどうかを確認します。
この検査には、最大幅と最大行数の 1 つまたは 2 つのパラメータが必要です。行数を指定しない場合は、1 行のテキストと判断されます。
使用するフォントは font-* ディレクティブ(参照 動作のカスタマイズ)で設定できます。例えば、次の設定の翻訳フラグは、ubuntu のフォント サイズ 22 で表示するテキストを、2 行 500 ピクセルに収める設定:
max-size:500:2, font-family:ubuntu, font-size:22
ヒント
Component configuration 内の font-* ディレクティブを設定して、コンポーネント内のすべての文字列に同じフォントを設定できます。文字列ごとに設定することが必要な場合に備えて、文字列ごとにこれらの値を上書きできます。
replacements: フラグは、文字列を検査する前に配置して表示する場合にも便利です。
\n の不一致¶
\n の数が原文と一致しないもの
通常、エスケープされた改行はプログラムの出力をフォーマットする際に重要です。翻訳の \n リテラルの数が原文と一致しない場合、検査で不合格となります。
コロンの不一致¶
原文と翻訳の一方の末尾がコロンではない
原文から翻訳にコロンが複製されているか検査します。コロンの有無は、それが属していないさまざまな言語についても検査されます(中国語または日本語)。
省略記号の不一致¶
原文と翻訳の一方が省略記号で終わっていない
原文から翻訳に末尾の省略記号が複製されているか検査します。これは、3 つのドット (…) ではなく、実際の省略記号 (...) のみを検査します。
省略記号は通常、印刷では 3 つのドットよりも綺麗に表示され、音声合成ではよりよく聞こえます。
感嘆符の不一致¶
原文と翻訳の一方が感嘆符で終わっていない
原文から翻訳に感嘆符が複製されているか検査します。感嘆符の有無は、感嘆符を持たないさまざまな言語についても検査されます(中国語、日本語、韓国語、アルメニア語、リンブ語、ミャンマー語、またはンコ語)。
終止符の不一致¶
原文と翻訳の一方が終止符で終わっていない
原文から翻訳に終止符止が複製されているか検査します。終止符の有無は、その終止符が属していない複数の言語(中国語、日本語、デーヴァナーガリー文字またはウルドゥー語)について検査します。
疑問符の不一致¶
原文と翻訳の一方が疑問符で終わっていない
原文から翻訳に疑問符が複製されているか検査します。疑問符の有無は、疑問符を持たない複数の言語(アルメニア語、アラビア語、中国語、韓国語、日本語、エチオピア語、ヴァイ語またはコプト語)についても検査します。
セミコロンの不一致¶
原文と翻訳の一方がセミコロンで終わってない
原文から翻訳に末尾のセミコロンが複製されているか検査します。これは、デスクトップ ファイルなどのエントリの書式を維持する場合に便利です。
複数形の不足¶
一部の複数形は翻訳されていない
原文のすべての複数形が翻訳されているか検査します。各複数形の使用方法の詳細については、文字列の定義で確認できます。
複数形を記入しないと、複数形が使用されているときに何も表示されないことがあります。
プレースホルダー¶
翻訳にはいくつかのプレースホルダーが足りない
バージョン 3.9 で追加.
バージョン 4.3 で変更: 正規表現をプレースホルダーとして使用できる。
一部のプレースホルダーが翻訳に欠けています。これらは翻訳ファイルから抽出されるか、placeholders フラグを使用して手動で定義します。フラグはコロンで区切り、スペースを含む文字列は引用符で囲んで使用します。
placeholders:$URL$:$TARGET$:"some long text"
プレースホルダに構文がある場合は、正規表現が使用できる:
placeholders:r"%[^% ]%"
参考
句読点のスペース¶
句読点記号の前にノーブレークスペースがない
バージョン 3.9 で追加.
句読点記号(感嘆符、疑問符、セミコロン、コロン)の前に改行できないスペースがあるか検査します。このルールは、フランス語やブルトン語などの、句読点記号の前のスペースはタイポグラフィの規則に準じる一部の言語でのみ使用されます。
正規表現¶
翻訳は正規表現に一致しない
バージョン 3.9 で追加.
翻訳は正規表現に一致しません。式は、翻訳ファイルから抽出するか、regex フラグを使用して手動で定義します。
regex:^foo|bar$
文末の空白¶
原文と翻訳の文末のスペースが一致しない
原文から翻訳に末尾のスペースが複製されているか検査します。
末尾のスペースは、通常、隣接する要素をスペースに入れるため、削除するとレイアウトが壊れることがあります。
未翻訳の翻訳文¶
原文と翻訳は同一です
原文と対応する翻訳文字列が、複数の形式の少なくとも 1 つまで同一である場合に発生します。すべての言語に共通する一部の文字列は無視され、さまざまなマークアップが除去されます。これにより、誤検出の数が減ります。
この検査は、誤って翻訳されていない文字列を見つけるのに便利です。
この検査のデフォルトの動作では、内蔵したブラックリストから単語を検査対象から除外します。これは頻繁に翻訳されない単語です。これは、複数の言語で同じ 1 つの単語だけで構成される短い文字列での誤検出を避けるために便利です。このブラックリストを無効にするには、文字列またはコンポーネントに strict-same フラグを追加します。
安全でない HTML¶
翻訳には安全でない HTML マークアップが含まれている
バージョン 3.9 で追加.
翻訳には、安全でない HTML マークアップが含まれています。この検査は safe-html フラグ(参照 動作のカスタマイズ)を使用して有効にしなければなりません。マークアップを自動的にサニタイズできる autofixer も付属しています。
参考
HTML の検査は、Mozilla が開発した Bleach library によって行われます。
URL¶
翻訳に URL が含まれていない
バージョン 3.5 で追加.
翻訳に URL が含まれていません。これは、ユニットが URL を含むとマークされている場合にのみ起動します。その場合、翻訳は有効な URL であることが必要です。
XML マークアップ¶
翻訳内の XML が原文と一致しない
これは通常、出力結果が異なることを意味します。ほとんどの場合、これは翻訳の変更による望ましい結果ではありませんが、場合によっては変更されることもあります。
原文から翻訳に XML タグが複製されているか検査します。
ゼロ幅スペース¶
翻訳には余分なゼロ幅のスペース文字が含まれている
単語内でのメッセージの改行(ワードラッピング)には、半角スペース(<U+200B>)文字を使用します。
通常は誤って挿入するため、この検査は翻訳中に検出した時点で起動します。この文字を使用すると、一部のプログラムで問題が発生することがあります。
原文検査¶
原文検査は、開発者が原文の品質を向上させるため便利です。
省略記号¶
文字列では、省略記号 (…) の代わりに 3 つのドット (...) が使われています
これは、文字列で省略記号 (...) を使用すべきところで、3 つのドット (…) を使用すると不合格となります。
ほとんどの場合、Unicode 文字を使用する方が適切な方法であり、表示の品質も高くなります。また、音声合成を使用する方が適切な場合もあります。
複数の検査で不合格¶
複数の言語の翻訳は、検査で不合格となっている
この文字列の翻訳の多くは、品質検査で不合格となっています。これは通常、原文を改善する方法が何かあるという意味です。
この検査の不合格は、文字列の末端の終止符の欠落、または翻訳者が翻訳で修正する傾向がある同様のささいな問題によって引き起こされることが多いが、原文で修正することをお勧めします。
複数の無名変数¶
文字列には複数の無名の変数があり、翻訳者がそれらを並べ替えることはできない
バージョン 4.1 で追加.
文字列内に複数の名前のない変数があるため、翻訳者がそれらを並べ替えることはできません。
代わりに名前付き変数を使用して、翻訳者が変数の順序を変更できるように検討してください。
複数形の除外¶
文字列を複数形として解釈するが、複数形のつづりは使用しない
文字列を複数形として解釈するが、複数形のつづりは使用しない。翻訳システムがこれに対応している場合は、複数形を認識するつづりを使用することが必要です。
Python の Gettext 使用例:
from gettext import ngettext
print ngettext("Selected %d file", "Selected %d files", files) % files