检查并修正¶
定制的自动修正¶
还可以应用除了自动修正以外自己的自动修正,并将它们包括到 AUTOFIX_LIST 。
自动修复很强大,但可能导致损坏;写脚本的时候要小心。
例如,后面的自动修复会将每次出现的字符串 foo 在翻译中替换为 bar :
#
# Copyright © 2012 - 2021 Michal Čihař <michal@cihar.com>
#
# This file is part of Weblate <https://weblate.org/>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
#
from django.utils.translation import gettext_lazy as _
from weblate.trans.autofixes.base import AutoFix
class ReplaceFooWithBar(AutoFix):
"""Replace foo with bar."""
name = _("Foobar")
def fix_single_target(self, target, source, unit):
if "foo" in target:
return target.replace("foo", "bar"), True
return target, False
为了安装定制的检查,在 AUTOFIX_LIST 中为 Python 类提供完全合规的路径,请参见 定制的质量检查、插件和自动修复 。
使用标志定制行为¶
可以在每个源字符串(在源字符串复核中,请参见 源字符串另外的信息 )或在 组件配置 (翻译标记) 中精细调整 Weblate的行为。一些文件格式允许直接在格式中指定标记(请参见 支持的文件格式 )。
标记用逗号分隔,参数用冒号分隔。可以在字符串中使用引号来包含空白字符或特定字符。例如:
placeholders:"special:value":"other value", regex:.*
这里是现在能接受的标记的列表:
rst-text将文本视为 reStructuredText 文档,影响 未更改的翻译 。
md-text将文本看作 Markdown 文件。
dos-eol使用 DOS 的行末标记,而不是 Unix的(
\r\ninstead of\n)。url字符串应该只包括 URL 。
safe-html字符串应该是 HTML 安全的,请参见 不安全的 HTML 网站 。
read-only字符串应该只读,并且不能在 Weblate 中编辑。请参见 只读字符串 。
priority:N字符串的优先级。高优先级的字符串首先出现被翻译。默认的优先级是 100 ,字符串的优先级越高,就会越早安排翻译。
max-length:N将字符串的最大长度限制为 N 个字符,请参见 译文最大长度。
xml-textfont-family:NAME定义 font-family 来提供检查,请参见 管理字型 。
font-weight:WEIGHT定义 font-weight 来提供检查,请参见 管理字型 。
font-size:SIZE定义 font-size 来提供检查,请参见 管理字型 。
font-spacing:SPACING定义渲染检查的字母间隔,请参见 管理字型 。
placeholders:NAME:NAME2:...翻译中需要的占位字符串,请参见 占位符 。
replacements:FROM:TO:FROM2:TO2...当检查结果文本参数时执行替换(例如在 最大翻译大小 或 译文最大长度 中)。这一典型应用的情况拓展了非译元素,确保匹配那些即使使用了长值的文本,例如 placements:%s:”John Doe”`` 。
variants:SOURCE将此字符串标记为具有匹配源的字符串的变体。见 字符串变量。
regex:REGEX用于匹配翻译文件的正则表达式,详见 正则表达式 。
forbiddenIndicates forbidden translation in a glossary, see 禁止的翻译.
python-format,c-format,php-format,python-brace-format,javascript-format,c-sharp-format,java-format,java-messageformat,lua-format,auto-java-messageformat,qt-format,qt-plural-format,ruby-format,vue-format将所有字符串视为格式字符串,影响 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 格式化字符串, 未更改的翻译.
strict-same使用内建的单词黑名单,来避免“没有翻译”的检查提示。请参见 未更改的翻译 。
check-glossary启用“未遵循词汇表”质量检查。
ignore-bbcode跳过“ BBcode 标记”质量检查。
ignore-duplicate跳过“连续重复的单词”质量检查。
ignore-check-glossary跳过“未遵循词汇表”质量检查。
ignore-double-space跳过“双空格”质量检查。
ignore-angularjs-format跳过“ AngularJS 插补字符串”质量检查。
ignore-c-format跳过“ C 格式”质量检查。
ignore-c-sharp-format跳过“ C# 格式”质量检查。
ignore-es-format跳过 “ECMAScript 模板文本” 质量检查。
ignore-i18next-interpolation跳过“ i18next 插补”质量检查。
ignore-java-format跳过“ Java 格式”质量检查。
ignore-java-messageformat跳过“ Java MesseageFormat ”质量检查。
ignore-javascript-format提高过“JavaScript 格式”质量检查。
ignore-lua-format跳过 “Lua 格式”质量检查。
ignore-percent-placeholders跳过“百分号占位符”质量检查。
ignore-perl-format跳过“ Perl 格式”质量检查。
ignore-php-format跳过“ PHP 格式”质量检查。
ignore-python-brace-format跳过“ Python brace 格式”质量检查。
ignore-python-format跳过“ Python 格式”质量检查。
ignore-qt-format跳过“ Qt 格式”质量检查。
ignore-qt-plural-format跳过“Qt plural 格式”质量检查。
ignore-ruby-format跳过“ Ruby 格式”质量检查。
ignore-vue-format跳过“ Vue I18n 格式”质量检查。
ignore-translated跳过“已被翻译”质量检查。
ignore-inconsistent跳过“不一致的”质量检查。
ignore-kashida跳过“已使用 Kashida 字符”质量检查。
ignore-md-link跳过“ Markdown 链接”质量检查。
ignore-md-reflink跳过“ Markdown 引用”质量检查。
ignore-md-syntax跳过“ Markdown 语法”质量检查。
ignore-max-length跳过“译文最大长度”质量检查。
ignore-max-size跳过“译文最大尺寸”质量检查。
ignore-escaped-newline跳过“换行符 n 不匹配”质量检查。
ignore-end-colon跳过 “不匹配的冒号” 质量检查。
ignore-end-ellipsis跳过 “不匹配的省略号” 质量检查。
ignore-end-exclamation跳过 “不匹配的感叹号” 质量检查。
ignore-end-stop跳过 “不匹配的句号” 质量检查。
ignore-end-question跳过 “不匹配的问号” 质量检查。
ignore-end-semicolon跳过 “不匹配的分号” 质量检查。
ignore-newline-count跳过“不匹配的断行”质量检查。
ignore-plurals跳过“缺少复数形式”质量检查。
ignore-placeholders跳过“占位符”质量检查。
ignore-punctuation-spacing跳过“标点间距”质量检查。
ignore-regex跳过“正则表达式”指令检查。
ignore-same-plurals跳过“相同复数”质量检查。
ignore-begin-newline跳过“换行开头”质量检查。
ignore-begin-space跳过“空格开头”质量检查。
ignore-end-newline跳过“换行结尾”质量检查。
ignore-end-space跳过“空格结尾”质量检查。
ignore-same跳过“未更改的翻译”质量检查。
ignore-safe-html跳过“不安全的 HTML 网站”质量检查。
ignore-url跳过“ URL ”质量检查。
ignore-xml-tags跳过“ XML 标记”质量检查。
ignore-xml-invalid跳过“ XML 语法”质量检查。
ignore-zero-width-space跳过“零宽空格”质量检查。
ignore-ellipsis跳过“省略号”质量检查。
ignore-long-untranslated跳过“长期未翻译”质量检查。
ignore-multiple-failures跳过“多项检查失败”质量检查。
ignore-unnamed-format跳过“多个未命名的变量”质量检查。
ignore-optional-plural跳过“未复数化”质量检查。
注解
通常规则是,任何检查都使用识别文字来命名 ignore-* ,所以能够将规则应用在定制检查中。
每个源字符串的设置,在 组件配置 设置中,并且在翻译文件自身中(例如在 GNU gettex 中),能够理解这些标记。
强制检查¶
3.11 新版功能.
你可以通过设置 组件配置 中的:ref:component-enforced_checks ,来配置不能省略的检查列表。列出的每个检查在用户界面中都不能省略,并且检查失败的任何字符串都被标记为 Needs editing (请参见 翻译状态)。
管理字型¶
3.7 新版功能.
提示
Fonts uploaded into Weblate are used purely for purposes of the 最大翻译大小 check, they do not have an effect in Weblate user interface.
用于计算呈现文本需要的尺寸的 :ref: ‘ check-max-size ‘检查需要字体被加载进 Weblate 并被一个翻译标识选中 (见 使用标志定制行为)。
在您的翻译项目 Manage 菜单下 Fonts 中的 Weblate 字体管理工具提供了接口来上传并管理字体。可以上传 TrueType 或 OpenType 字体,设置 font-groups 并在检查中使用它们。
字型组允许为不同语言确定不同字型,这是非拉丁语言中典型需要的:
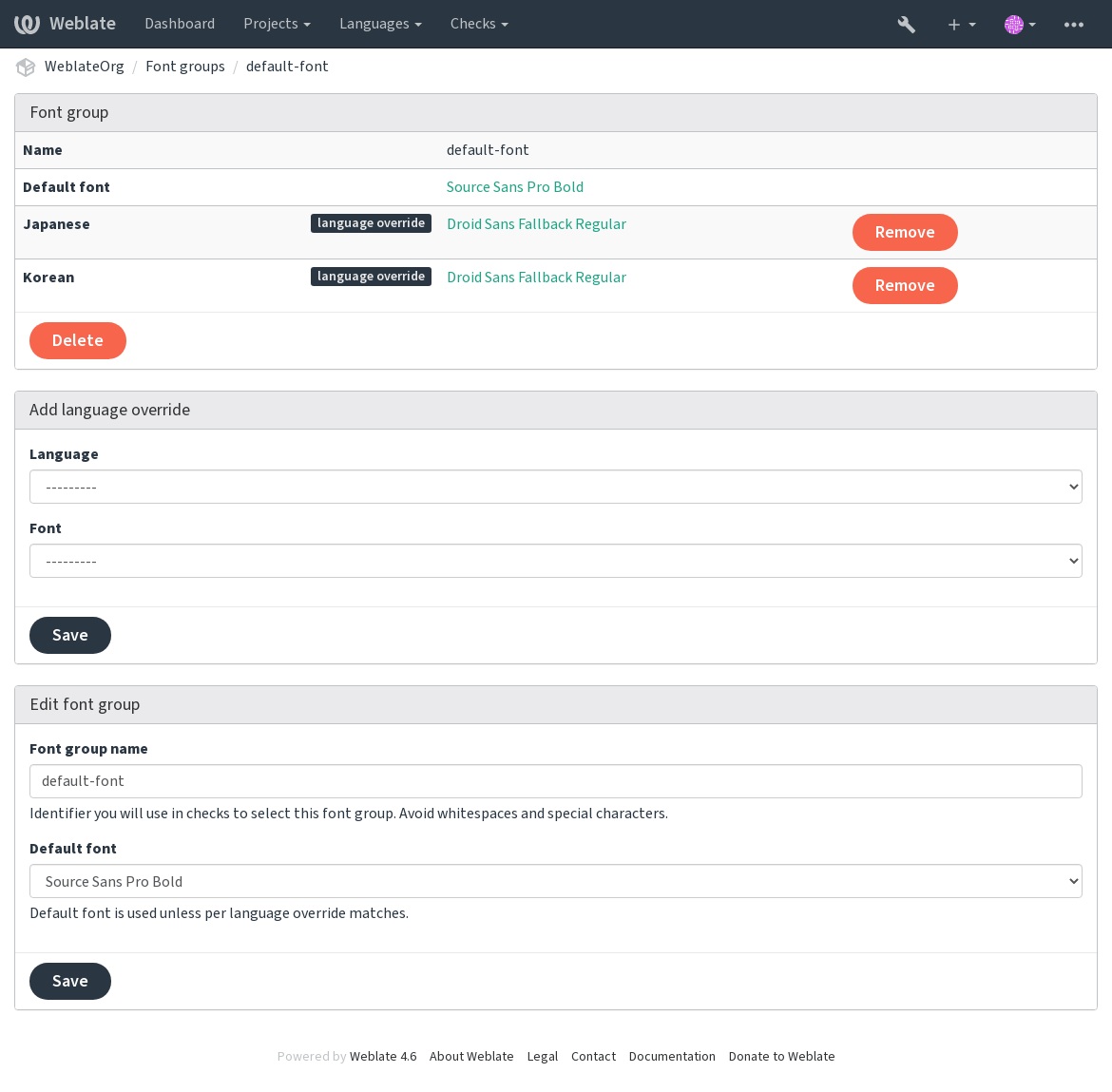
字型组通过名称识别,名称不能包含空白字符或特殊字符,这使它能够容易地用在检查定义中:
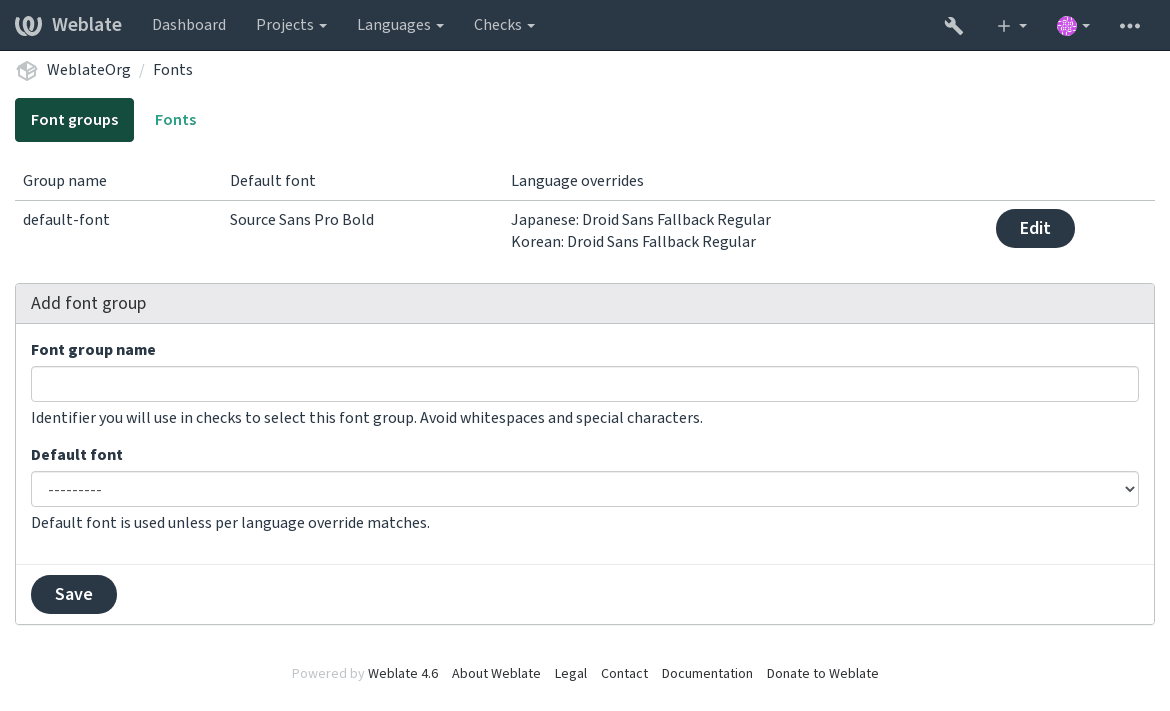
字型族和样式在上传后自动识别:
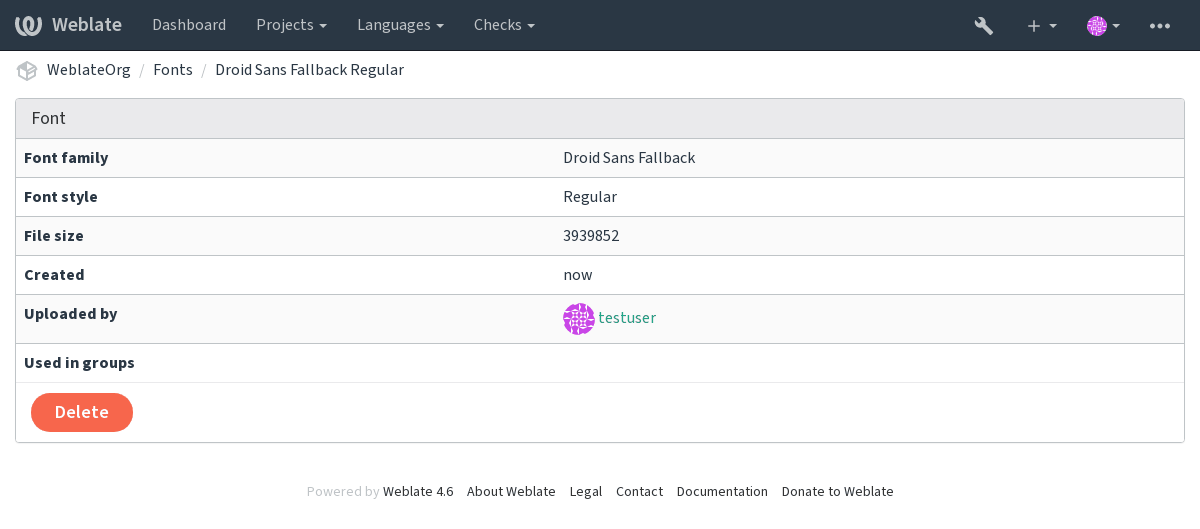
可以将几种字型加载到 Weblate 中:
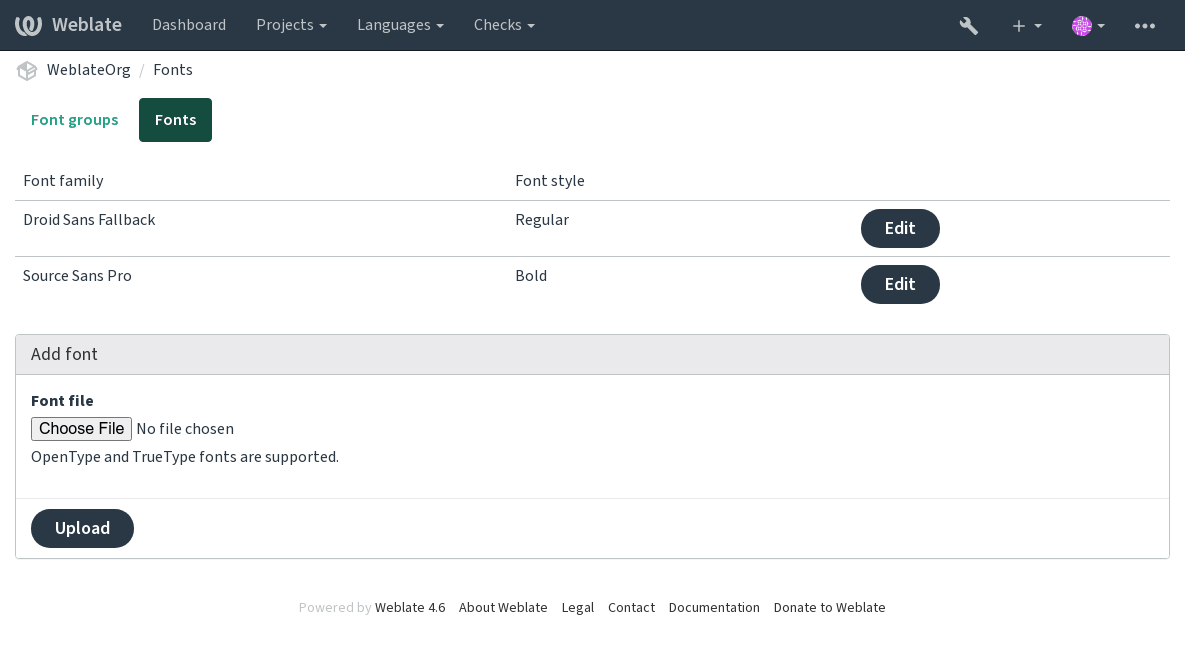
为了使用字型来检查字符串长度,将适当的标记传递给它 (请参见 使用标志定制行为)。可能会需要后面这些:
max-size:500确定最大宽度。
font-family:ubuntu确定字型组,通过指定其识别文字来使用。
font-size:22确定字号。
编写自己的检查¶
Weblate 内建了很大范围的质量检查,(请参见 质量检查 ),尽管可能没有覆盖想要检查的所有内容。可以使用 CHECK_LIST 来调整执行检查的列表,也可以添加定制的检查。
子类 weblate.checks.Check
设置一些属性。
应用
check(如果想要处理代码中的复数的话)或check_single方法(它将为你完成)。
一些例子:
为了安装定制的检查,在 CHECK_LIST 中为 Python 类提供完全合格的路径,请参见 定制的质量检查、插件和自动修复 。
检查翻译文本不含有 “ foo ”¶
这是非常简单的检查,只检查翻译中是否丢失了字符串“ foo ”。
#
# Copyright © 2012 - 2021 Michal Čihař <michal@cihar.com>
#
# This file is part of Weblate <https://weblate.org/>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
#
"""Simple quality check example."""
from django.utils.translation import gettext_lazy as _
from weblate.checks.base import TargetCheck
class FooCheck(TargetCheck):
# Used as identifier for check, should be unique
# Has to be shorter than 50 characters
check_id = "foo"
# Short name used to display failing check
name = _("Foo check")
# Description for failing check
description = _("Your translation is foo")
# Real check code
def check_single(self, source, target, unit):
return "foo" in target
检查捷克语翻译文本的复数差异¶
使用语言信息来检查,验证捷克语中的两种复数形式不同。
#
# Copyright © 2012 - 2021 Michal Čihař <michal@cihar.com>
#
# This file is part of Weblate <https://weblate.org/>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
#
"""Quality check example for Czech plurals."""
from django.utils.translation import gettext_lazy as _
from weblate.checks.base import TargetCheck
class PluralCzechCheck(TargetCheck):
# Used as identifier for check, should be unique
# Has to be shorter than 50 characters
check_id = "foo"
# Short name used to display failing check
name = _("Foo check")
# Description for failing check
description = _("Your translation is foo")
# Real check code
def check_target_unit(self, sources, targets, unit):
if self.is_language(unit, ("cs",)):
return targets[1] == targets[2]
return False
def check_single(self, source, target, unit):
"""We don't check target strings here."""
return False