检查和修正#
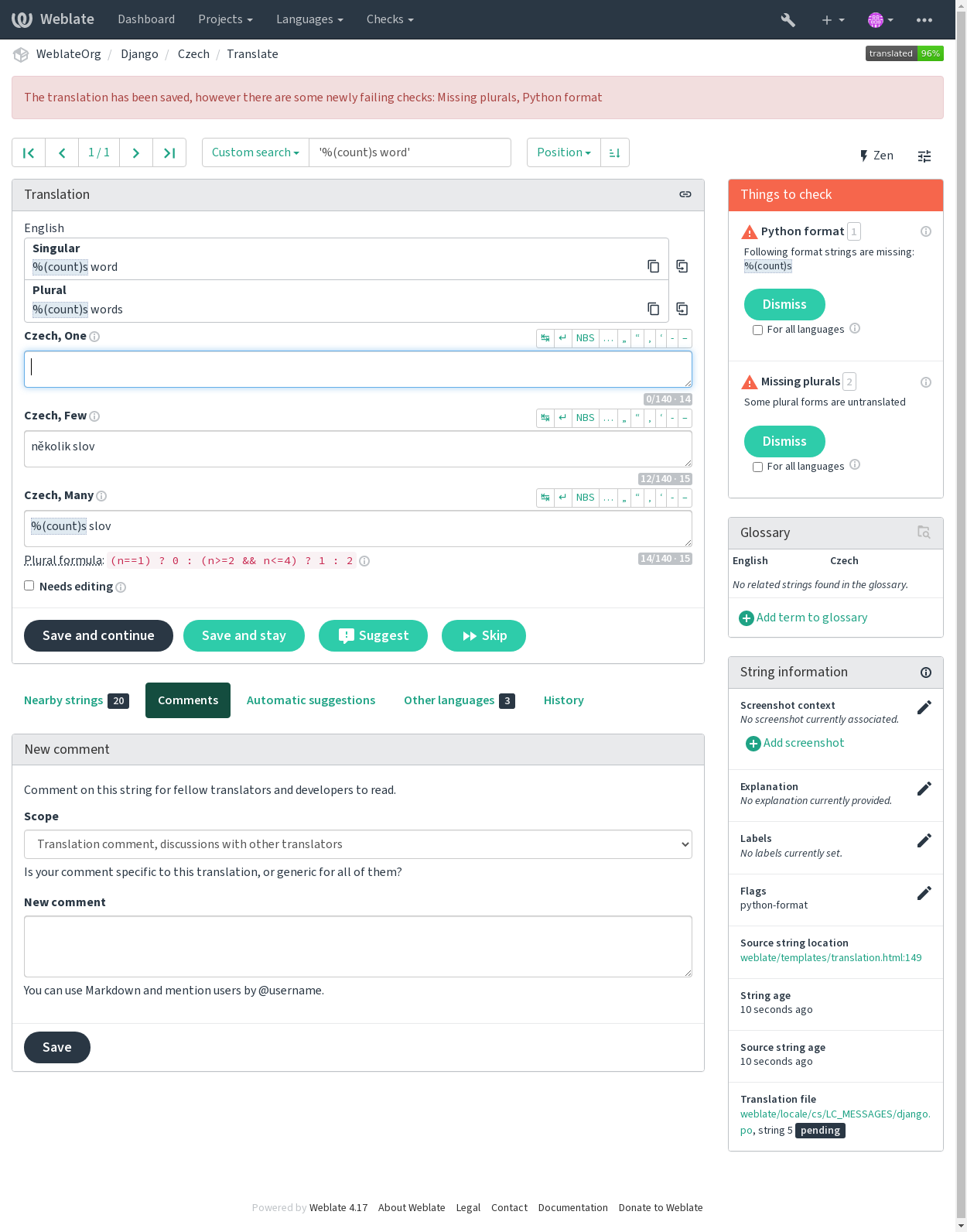
质量检查有助于发现常见的翻译错误,确保翻译质量良好。如果出现误报,则可以忽略这些检查。
一旦提交了未通过检查的译文,会立即向用户显示:
自动修正#
除了 质量检查 外,Weblate 还可以自动修复翻译字符串中的一些常见错误。谨慎使用它,不要使其增加翻译错误。
参见
拖尾省略号替换#
用省略号 (…) 替换拖尾点 (...) 来保持和源字符串的一致。
零宽空格删除#
译文中通常不希望出现零宽空格。此修补会删除它,除非源字符串中也存在零宽空格。
控制字符删除#
从翻译中删除任何控制字符。
梵文 danda#
用梵文 danda (।) 替换梵文中错误的句号。
不安全的 HTML 清理#
使用 ``safe-html``标记开启时会清理 HTML markup。
参见
修复首尾空白#
使首尾空白和源字符串保持一致。可使用 ignore-begin-space 和 ignore-end-space 标记精确调整行为以跳过字符串的处理部分。
质量检查#
Weblate 对字符串进行了广泛的质量检查。以下部分将对它们进行更详细的描述。还有针对特定语言的检查。如果有错误报告,请将缺陷提交。
参见
译文检查#
在每次翻译更改时执行,帮助译者提交高质量的翻译。
BBCode 标记#
- 概要:
译文中的 BBCode 和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.BBCodeCheck- 检查的标识符:
bbcode- 忽略的标记:
ignore-bbcode
BBCode 表示简单的标记,例如以粗体或斜体突出显示消息的重要部分。
此检查确保在翻译中也找到它们。
备注
目前检测 BBCode 的方法非常简单,所以此检查可能会产生误报。
连续重复的单词#
在 4.1 版本加入.
- 概要:
一行文本中包含同一单词两次:
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.duplicate.DuplicateCheck- 检查的标识符:
duplicate- 忽略的标记:
ignore-duplicate
检查译文中是否有连续重复的单词出现。这通常表示译文中存在错误。
提示
此检查包括特定语言的规则,以避免误报。如果在您的情况下错误触发,请告诉我们。请参阅 在 Weblate 中汇报问题。
不遵循术语表#
在 4.5 版本加入.
- 概要:
译文未遵循术语表中定义的术语。
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.glossary.GlossaryCheck- 检查的标识符:
check_glossary- 启用的标记:
check-glossary- 忽略的标记:
ignore-check-glossary
必须使用标记 check-glossary 以开启此检查(请参阅 使用标记定制行为)。请在启用它之前考虑以下事项:
它进行精确的字符串匹配。预计术语表将包含所有变体中的术语。
根据术语表检查每条字符串的成本很高,它会减慢 Weblate 中涉及运行检查(如导入字符串或翻译)的任何操作。
它还使用 未更改的译文 中不可翻译的词汇表术语。
双空格#
- 概要:
译文包含双空格
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.DoubleSpaceCheck- 检查的标识符:
double_space- 忽略的标记:
ignore-double-space
检查翻译中是否存在双空格,以避免其他与空格相关的检查出现误报。
当在原文中找到双空格时,检查为假,这意味着双空格是故意的。
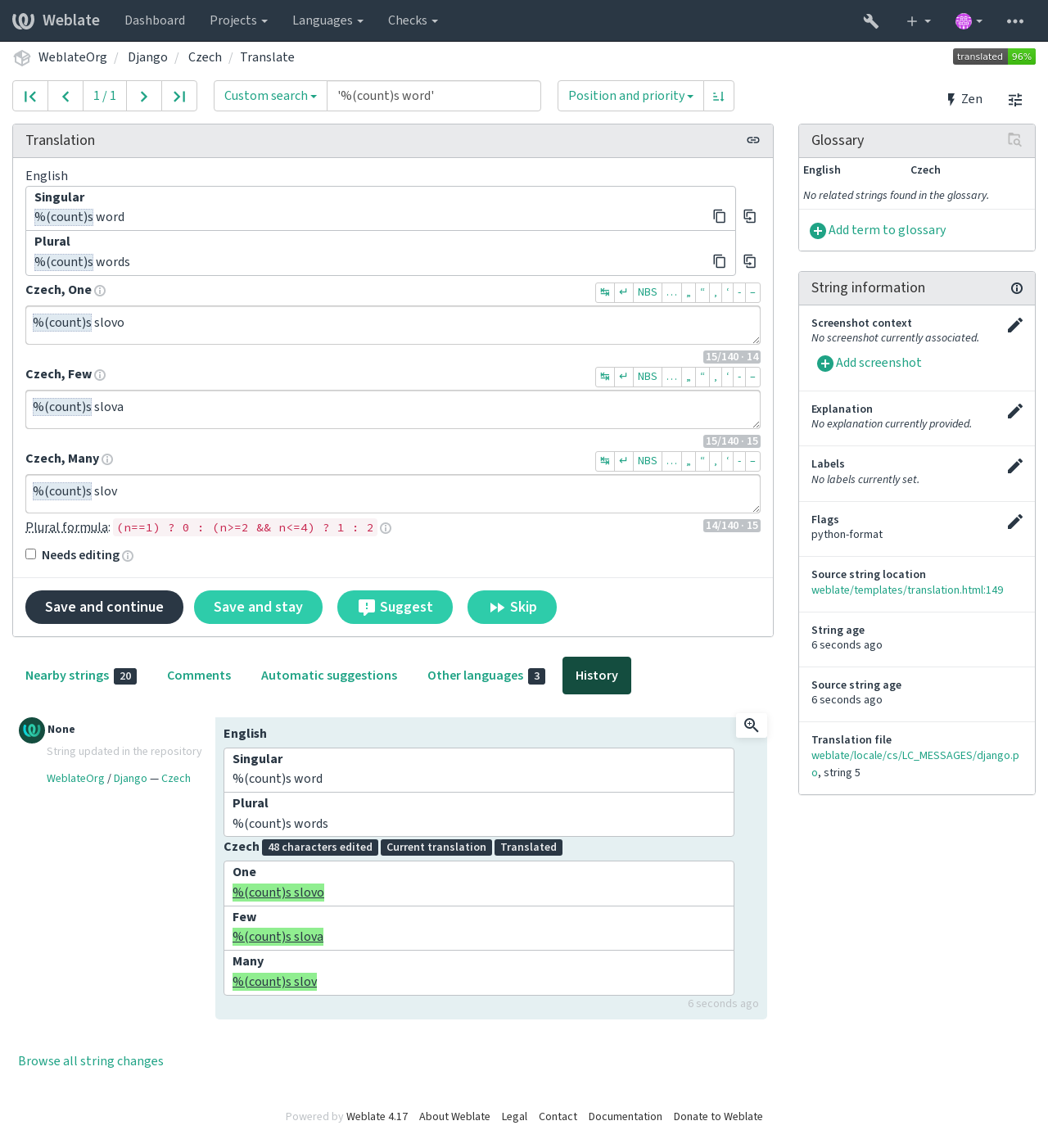
格式化字符串#
检查字符串中的格式化是否在原文和译文中都得到了复制。在译文中省略格式字符串通常会导致严重的问题,所以字符串中的格式化通常应与原文匹配。
Weblate 支持检查多种语言的格式字符串。仅当适当地标记了字符串时(例如 C 格式为 c-format),才会自动启用该检查。Gettext 会自动添加它,但是对于其他文件格式,或者如果您的 PO 文件不是由 xgettext 生成的,您可能必须手动添加它。
可以按每单位(请参阅 源字符串另外的信息)或在 部件配置 中完成此操作。为每个部件定义它比较简单,但是如果该字符串未解释为格式化字符串,而碰巧使用了格式化字符串语法,则可能导致误报。
提示
如果 Weblate 中不提供特定格式的检查,则可以使用通用 占位符。
除了检查,这也将高亮格式化字符串,方便将它们插入到已翻译字符串:
AngularJS 插值字符串#
- 概要:
AngularJS 插值字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.angularjs.AngularJSInterpolationCheck- 检查的标识符:
angularjs_format- 启用的标记:
angularjs-format- 忽略的标记:
ignore-angularjs-format- 命名格式字符串示例:
您的余额是 {{amount}} {{ currency }}
参见
C 格式#
- 概要:
C 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.CFormatCheck- 检查的标识符:
c_format- 启用的标记:
c-format- 忽略的标记:
ignore-c-format- 简单格式字符串示例:
这里有 %d 个苹果- 位置格式字符串示例:
您的余额是 %1$d %2$s
C# 格式#
- 概要:
C# 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.CSharpFormatCheck- 检查的标识符:
c_sharp_format- 启用的标记:
c-sharp-format- 忽略的标记:
ignore-c-sharp-format- 位置格式字符串示例:
这里有 {0} 个苹果
ECMAScript 模板字面量#
- 概要:
ECMAScript 模板字面量和原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.ESTemplateLiteralsCheck- 检查的标识符:
es_format- 启用的标记:
es-format- 忽略的标记:
ignore-es-format- 插值示例:
这里有 ${number} 个苹果
i18next 插值#
在 4.0 版本加入.
- 概要:
i18next 插值和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.I18NextInterpolationCheck- 检查的标识符:
i18next_interpolation- 启用的标记:
i18next-interpolation- 忽略的标记:
ignore-i18next-interpolation- 插值示例:
这里有 {{number}} 个苹果- 嵌套示例:
这里有 $t(number) 个苹果
参见
ICU MessageFormat#
在 4.9 版本加入.
- 概要:
ICU MessageFormat 字符串语法错误和/或占位符不匹配。
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.icu.ICUMessageFormatCheck- 检查的标识符:
icu_message_format- 启用的标记:
icu-message-format- 忽略的标记:
ignore-icu-message-format- 插值示例:
这里有 {number, plural, one {1 个苹果} other {# 个苹果}}.
此检查支持纯 ICU MessageFormat 消息以及带有简单 XML 标记的 ICU。您可以使用 配置此检查的行为 icu-flags:*,方法是选择支持 XML 或禁用某些子检查。例如,以下标记启用 XML 支持,同时禁用多个子消息的验证:
icu-message-format, icu-flags:xml:-plural_selectors
|
启用对简单 XML 标记的支持。默认情况下,XML 标记被松散地解析。如果杂散 |
|
启用对严格的XML标签的支持。所有 |
|
停用在编辑器中突出显示占位符。 |
|
禁用要求子信息有 |
|
跳过检查子消息选择器是否与原文匹配。 |
|
跳过检查占位符类型是否与原文匹配。 |
|
跳过检查是否存在源字符串中不存在的占位符。 |
|
跳过检查是否有源字符串中存在的占位符丢失。 |
此外当 strict-xml 未启用但 xml 已启用时,您可以使用该 icu-tag-prefix:PREFIX 标志来要求所有 XML 标记都以特定字符串开头。例如,以下标志只允许匹配以 开头的 XML 标记 <x::
icu-message-format, icu-flags:xml, icu-tag-prefix:"x:"
这将匹配 <x:link>点击此处</x:link> 但不匹配 <strong>这里</strong> 。
Java 格式#
- 概要:
Java 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.JavaFormatCheck- 检查的标识符:
java_printf_format- 启用的标记:
java-printf-format- 忽略的标记:
ignore-java-printf-format- 简单格式字符串示例:
这里有 %d 个苹果- 位置格式字符串示例:
您的余额是 %1$d %2$s
在 4.14 版本发生变更: 这曾经由 java-format 标记切换,为了与 GNU gettext 保持一致而进行了更改。
参见
Java MessageFormat#
- 概要:
Java MessageFormat 字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.JavaMessageFormatCheck- 检查的标识符:
java_format- 无条件启用的标记:
java-format- 启用自动检测的标记:
auto-java-messageformat仅当源中存在格式字符串时才启用检查- 忽略的标记:
ignore-java-format- 位置格式字符串示例:
这里有 {0} 个苹果
在 4.14 版本发生变更: 这曾经由 java-messageformat 标记切换,为了与 GNU gettext 保持一致而进行了更改。
该检查验证格式字符串对Java MessageFormat 类有效。除了匹配花括号中的格式字符串外,它还验证单引号,因为它们具有特殊含义。无论何时,都应把单引号写成 ''. 如果没有配对,它将被视为引用的开始,并且在呈现字符串时不会显示。
JavaScript 格式#
- 概要:
JavaScript 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.JavaScriptFormatCheck- 检查的标识符:
javascript_format- 启用的标记:
javascript-format- 忽略的标记:
ignore-javascript-format- 简单格式字符串示例:
这里有 %d 个苹果
Lua 格式#
- 概要:
Lua 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.LuaFormatCheck- 检查的标识符:
lua_format- 启用的标记:
lua-format- 忽略的标记:
ignore-lua-format- 简单格式字符串示例:
这里有 %d 个苹果
Object Pascal 格式#
- 概要:
Object Pascal 格式字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.ObjectPascalFormatCheck- 检查的标识符:
object_pascal_format- 启用的标记:
object-pascal-format- 忽略的标记:
ignore-object-pascal-format- 简单格式字符串示例:
这里有 %d 个苹果
百分比占位符#
在 4.0 版本加入.
- 概要:
提供的百分比占位符与原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.PercentPlaceholdersCheck- 检查的标识符:
percent_placeholders- 启用的标记:
percent-placeholders- 忽略的标记:
ignore-percent-placeholders- 简单格式字符串示例:
这里有 %number% 个苹果
参见
Perl 格式#
- 概要:
Perl 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.PerlFormatCheck- 检查的标识符:
perl_format- 启用的标记:
perl-format- 忽略的标记:
ignore-perl-format- 简单格式字符串示例:
这里有 %d 个苹果- 位置格式字符串示例:
您的余额是 %1$d %2$s
参见
PHP 格式#
- 概要:
PHP 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.PHPFormatCheck- 检查的标识符:
php_format- 启用的标记:
php-format- 忽略的标记:
ignore-php-format- 简单格式字符串示例:
这里有 %d 个苹果- 位置格式字符串示例:
您的余额是 %1$d %2$s
Python brace 格式#
- 概要:
Python 大括号格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.PythonBraceFormatCheck- 检查的标识符:
python_brace_format- 启用的标记:
python-brace-format- 忽略的标记:
ignore-python-brace-format- 简单格式字符串:
这里有 {} 个苹果- 命名格式字符串示例:
您的余额是 {amount} {currency}
Python 格式#
- 概要:
Python 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.PythonFormatCheck- 检查的标识符:
python_format- 启用的标记:
python-format- 忽略的标记:
ignore-python-format- 简单格式字符串:
这里有 %d 个苹果- 命名格式字符串示例:
您的余额是 %(amount)d %(currency)s
参见
Qt 格式#
- 概要:
Qt 格式字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.qt.QtFormatCheck- 检查的标识符:
qt_format- 启用的标记:
qt-format- 忽略的标记:
ignore-qt-format- 位置格式字符串示例:
这里有 %1 个苹果
Qt 复数格式#
- 概要:
Qt 复数格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.qt.QtPluralCheck- 检查的标识符:
qt_plural_format- 启用的标记:
qt-plural-format- 忽略的标记:
ignore-qt-plural-format- 复数格式字符串示例:
这里有 %Ln 个苹果
参见
Ruby 格式#
- 概要:
Ruby 格式的字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.ruby.RubyFormatCheck- 检查的标识符:
ruby_format- 启用的标记:
ruby-format- 忽略的标记:
ignore-ruby-format- 简单格式字符串示例:
这里有 %d 个苹果- 位置格式字符串示例:
您的余额是 %1$f %2$s- 命名格式字符串示例:
您的余额是 %+.2<amount>f %<currency>s- 命名模板字符串:
您的余额是 %{amount} %{currency}
Scheme 格式#
- 概要:
Scheme 格式字符串与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.SchemeFormatCheck- 检查的标识符:
scheme_format- 启用的标记:
scheme-format- 忽略的标记:
ignore-scheme-format- 简单格式字符串示例:
这里有 ~d 个苹果
参见
Vue I18n 格式化#
- 概要:
Vue I18n 格式化和原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.format.VueFormattingCheck- 检查的标识符:
vue_format- 启用的标记:
vue-format- 忽略的标记:
ignore-vue-format- 已命名格式:
这里有 {count} 个苹果- Rails i18n 格式化:
这里有 %{count} 个苹果- 链接的语言环境消息:
@:message.dio @:message.the_world!
曾被翻译过#
- 概要:
这条字符串在过去曾被翻译过
- 范围:
所有字符串
- 检查的类:
weblate.checks.consistency.TranslatedCheck- 检查的标识符:
translated- 忽略的标记:
ignore-translated
表示一条字符串已经被翻译。当译文已在版本控制系统(VCS)中恢复或以其他方式丢失时,可能会发生这种情况。
不一致的#
- 概要:
此字符串在此项目中有不止一种译文,或者在某些部件中未翻译。
- 范围:
所有字符串
- 检查的类:
weblate.checks.consistency.ConsistencyCheck- 检查的标识符:
inconsistent- 忽略的标记:
ignore-inconsistent
Weblate 检查一个项目内所有翻译中相同字符串的译文,以帮助您保持翻译的一致性。
在一个项目中对一条字符串的不同译文,检查会失败。这也会导致检查结果的不一致。你可以在 其它的出现位置 选项卡上找到这条字符串的其他译文。
此检查应用于项目中所有开启了 允许同步翻译 的部件。
提示
出于性能原因,检查可能不会发现所有不一致,它限制了匹配的数量。
备注
如果字符串在一个部件中被翻译,而在另一个部件中没有被翻译,这个检查也会启动。它可以作为一种快速的方法来手动处理在某些部件中未被翻译的字符串,只需点击显示在 其它的出现位置 选项卡中的每一行的 使用此译文 按钮。
您可以使用 自动翻译 附加部件来自动翻译已经在另一个部件中已翻译的新添加的字符串。
参见
使用了 Kashida 字母#
在 3.5 版本加入.
- 概要:
不应使用装饰性的 kashida 字母
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.KashidaCheck- 检查的标识符:
kashida- 忽略的标记:
ignore-kashida
装饰性的 Kashida 字母不能用于译文。这些也被称为 Tatweel。
Markdown 链接#
在 3.5 版本加入.
- 概要:
Markdown 链接和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.MarkdownLinkCheck- 检查的标识符:
md-link- 启用的标记:
md-text- 忽略的标记:
ignore-md-link
Markdown 链接和原文不一致。
参见
Markdown 引用#
在 3.5 版本加入.
- 概要:
Markdown 链接引用和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.MarkdownRefLinkCheck- 检查的标识符:
md-reflink- 启用的标记:
md-text- 忽略的标记:
ignore-md-reflink
Markdown 链接引用和原文不一致。
参见
Markdown 语法#
在 3.5 版本加入.
- 概要:
Markdown 语法与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.MarkdownSyntaxCheck- 检查的标识符:
md-syntax- 启用的标记:
md-text- 忽略的标记:
ignore-md-syntax
Markdown 语法与原文不匹配
译文最大长度#
- 概要:
译文不应超过给定长度
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.MaxLengthCheck- 检查的标识符:
max-length- 启用的标记:
max-length- 忽略的标记:
ignore-max-length
检查翻译的长度是否符合可用空间的要求。这只会检查翻译字符的长度。
与其他检查不同,该标记应设置为 key:value 对,如 max-length:100。
提示
这个检查看的是字符数,当使用比例字体来渲染文本时,这可能不是最好的衡量标准。最大译文长度 检查会检查文本的实际渲染。
replacements: 标志可能也有助于在检查字符串之前扩展可放置对象。
当同时使用 xml-text 标志时,长度计算会忽略 XML 标记。
最大译文长度#
- 概要:
译文不应超过给定长度
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.render.MaxSizeCheck- 检查的标识符:
max-size- 启用的标记:
max-size- 忽略的标记:
ignore-max-size
在 3.7 版本加入.
译文呈现的文本不应超过给定的大小。它使用换行呈现文本,并检查文本是否适合给定的边界。
此检查需要一个或两个参数 - 最大宽度和最大行数。如果未提供行数,则考虑一行文本。
您还可以通过 font-* 指令配置使用的字体(请参阅 使用标记定制行为),例如以下翻译标志说以 ubuntu 字体大小 22 呈现的文本应该适合两行和 500 像素:
max-size:500:2, font-family:ubuntu, font-size:22
提示
您可能希望在 部件配置 中设置 font-* 指令,以便为组件中的所有字符串配置相同的字体。如果您需要为每条字符串自定义它,您可以覆盖每条字符串的这些值。
replacements: 标志可能也有助于在检查字符串之前扩展可放置对象。
当同时使用 xml-text 标志时,长度计算会忽略 XML 标记。
不匹配的 \n#
- 概要:
译文中的 \n 个数与原文不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EscapedNewlineCountingCheck- 检查的标识符:
escaped_newline- 忽略的标记:
ignore-escaped-newline
通常转义的换行符对于格式化程序输出很重要。如果译文中的 \n 字面量与原文不匹配,则检查失败。
不匹配的冒号#
- 概要:
原文与译文没有都以冒号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndColonCheck- 检查的标识符:
end_colon- 忽略的标记:
ignore-end-colon
检查冒号是否在原文和译文之间复制。还检查了冒号是否存在于不属于它们的各种语言(中文或日语)。
参见
不匹配的省略号#
- 概要:
原文与译文没有都以省略号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndEllipsisCheck- 检查的标识符:
end_ellipsis- 忽略的标记:
ignore-end-ellipsis
检查结尾省略号是否在原文和译文之间复制。这只检查真正的省略号( … ),而不检查三个点( ... )。
在打印中,省略号通常比三个点更好,并且使用文本到语音转换听起来更好。
不匹配的感叹号#
- 概要:
原文与译文没有都以感叹号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndExclamationCheck- 检查的标识符:
end_exclamation- 忽略的标记:
ignore-end-exclamation
检查感叹号是否在原文和译文之间复制。还会检查感叹号是否存在不属于它们的各种语言(中文,日语,韩语,亚美尼亚语,林布语,缅甸语或Nko)。
不匹配的句号#
- 概要:
原文与译文没有都以句号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndStopCheck- 检查的标识符:
end_stop- 忽略的标记:
ignore-end-stop
检查是否在原文和译文之间复制了句号。检查句号是否存在不属于它们的各种语言(中文,日语,梵文或乌尔都语)。
参见
不匹配的问号#
- 概要:
原文与译文没有都以问号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndQuestionCheck- 检查的标识符:
end_question- 忽略的标记:
ignore-end-question
检查问号是否在原文和译文之间复制。对于不属于它们的各种语言(亚美尼亚语,阿拉伯语,中文,韩语,日语,埃塞俄比亚语,瓦伊语或科普特语),也会检查问号的存在。
参见
不匹配的分号#
- 概要:
原文与译文没有都以分号结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndSemicolonCheck- 检查的标识符:
end_semicolon- 忽略的标记:
ignore-end-semicolon
检查句子末尾的分号是否在原文和译文之间复制。
参见
不匹配的换行符#
- 概要:
译文中的换行数量和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.NewLineCountCheck- 检查的标识符:
newline-count- 忽略的标记:
ignore-newline-count
通常换行符对于格式化程序输出很重要。如果译文中的新行数与原文不匹配,则检查失败。
缺少复数形式#
- 概要:
某些复数形式未翻译
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.consistency.PluralsCheck- 检查的标识符:
plurals- 忽略的标记:
ignore-plurals
检查源字符串的所有复数形式是否已翻译。有关如何使用每个复数形式的详细信息,请参阅字符串定义。
在某些情况下,未能填写复数形式将导致在使用复数形式时不显示任何内容。
占位符#
在 3.9 版本加入.
- 概要:
译文缺少一些占位符
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.placeholders.PlaceholderCheck- 检查的标识符:
placeholders- 启用的标记:
placeholders- 忽略的标记:
ignore-placeholders
在 4.3 版本发生变更: 你可以使用正则表达式作为占位符。
在 4.13 版本发生变更: 使用 case-insensitive 标志时,占位符不区分大小写。
译文缺少一些占位符。这些可以从翻译文件中提取或使用 placeholders 标志手动定义,更多可以用冒号分隔,带空格的字符串可以引用:
placeholders:$URL$:$TARGET$:"some long text"
如果您有一些占位符语法,则可以使用正则表达式:
placeholders:r"%[^% ]%"
您还可以使用不区分大小写的占位符:
placeholders:$URL$:$TARGET$,case-insensitive
参见
标点间距#
在 3.9 版本加入.
- 概要:
双标点符号前缺少不可换行的空格
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.PunctuationSpacingCheck- 检查的标识符:
punctuation_spacing- 忽略的标记:
ignore-punctuation-spacing
检查双标点符号(感叹号、问号、分号和冒号)之前是否存在不可中断的空格。此规则仅在法语或布列塔尼语等少数选定语言中使用,其中双标点符号前的空格是排版规则。
正则表达式#
在 3.9 版本加入.
- 概要:
译文与正则表达式不匹配
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.placeholders.RegexCheck- 检查的标识符:
regex- 启用的标记:
regex- 忽略的标记:
ignore-regex
译文与正则表达式不匹配。该表达式从翻译文件中提取或使用 regex 标志手动定义:
regex:^foo|bar$
相同的复数形式#
- 概要:
一些复数形式采用了相同的译文
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.consistency.SamePluralsCheck- 检查的标识符:
same-plurals- 忽略的标记:
ignore-same-plurals
如果译文中某些复数形式重复,则检查失败。在大多数语言中,它们必须不同。
换行符开头#
- 概要:
原文与译文没有都以换行符开头
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.BeginNewlineCheck- 检查的标识符:
begin_newline- 忽略的标记:
ignore-begin-newline
换行符通常出现在源字符串中是有充分理由的,在使用翻译文本时,省略或添加可能会导致格式问题。
参见
空格开头#
- 概要:
原文与译文的开头空格数量不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.BeginSpaceCheck- 检查的标识符:
begin_space- 忽略的标记:
ignore-begin-space
字符串开头的空格通常用于界面中的缩进,因此保留很重要。
换行符结尾#
- 概要:
原文与译文没有都以换行结符尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndNewlineCheck- 检查的标识符:
end_newline- 忽略的标记:
ignore-end-newline
换行符通常出现在源字符串中是有充分理由的,在使用翻译文本时,省略或添加可能会导致格式问题。
参见
空格结尾#
- 概要:
原文与译文没有都以空格结尾
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.EndSpaceCheck- 检查的标识符:
end_space- 忽略的标记:
ignore-end-space
检查原文和译文之间是否复制了尾部的空格。
拖尾空格通常用于分隔相邻元素,因此删除它可能会破坏布局。
未更改的译文#
- 概要:
原文和译文毫无差异
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.same.SameCheck- 检查的标识符:
same- 忽略的标记:
ignore-same
如果原文和对应的译文字符串相同,至少到复数形式中的一种,则会发生这种情况。在所有语言中常见的一些字符串被忽略,并且各种标记被剥离。这减少了误报的数量。
此检查可以帮助查找错误未翻译的字符串。
此检查的默认行为是从检查中排除内置黑名单中的单词。这些单词经常被翻译。这对于避免短字符串的误报非常有用,短字符串仅由在多种语言中相同的单个单词组成。可以通过向字符串或组件添加 strict-same 标志来禁用此黑名单。
在 4.17 版本发生变更: 使用 check-glossary 标志(参见 不遵循术语表 ),不可翻译的术语表术语被排除在检查之外。
不安全的 HTML#
在 3.9 版本加入.
- 概要:
该译文使用了不安全的 HTML 标记
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.SafeHTMLCheck- 检查的标识符:
safe-html- 启用的标记:
safe-html- 忽略的标记:
ignore-safe-html
译文使用了不安全的 HTML 标记。必须使用 safe-html 标志启用此检查(请参阅 使用标记定制行为)。还有附带的自动修复程序,可以自动清理标记。
提示
当同时使用 md-text 标志时,也允许使用 Markdown 样式链接。
参见
HTML 检查的执行者是 Ammonia 库。
URL#
在 3.5 版本加入.
- 概要:
译文未包含 URL
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.URLCheck- 检查的标识符:
url- 启用的标记:
url- 忽略的标记:
ignore-url
译文不包含 URL。仅当单元被标记为包含 URL 时才会触发。在这种情况下,译文必须是有效的 URL。
XML 标记#
- 概要:
译文中的 XML 标签和原文不一致
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.XMLTagsCheck- 检查的标识符:
xml-tags- 忽略的标记:
ignore-xml-tags
这通常意味着生成的输出看起来会有所不同。在大多数情况下,这不是更改译文所期望的结果,但有时确实如此。
检查 XML 标记是否在原文和译文之间复制。
该检查对类 XML 字符串自动开启。某些情形下,你也许需要添加 xml-text 标记来强制打开它。
备注
此检查被 safe-html 标记禁用,因为它完成的 HTML 清理可能会生成无效 XML 的 HTML 标记。
XML 语法#
- 概要:
该译文不是有效的 XML
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.markup.XMLValidityCheck- 检查的标识符:
xml-invalid- 忽略的标记:
ignore-xml-invalid
此XML标记无效。
该检查对类 XML 字符串自动开启。某些情形下,你也许需要添加 xml-text 标记来强制打开它。
备注
此检查被 safe-html 标记禁用,因为它完成的 HTML 清理可能会生成无效 XML 的 HTML 标记。
零宽空格#
- 概要:
译文中含有额外的零宽空格字符
- 范围:
已翻译字符串
- 检查的类:
weblate.checks.chars.ZeroWidthSpaceCheck- 检查的标识符:
zero-width-space- 忽略的标记:
ignore-zero-width-space
零宽空格 (<U+200B>) 字符用于分隔单词中的消息(自动换行)。
由于它们通常是被错误插入的,一旦它们出现在翻译中,就会触发这个检查。一些程序在使用这个字符时可能会出现问题。
原文检查#
原文检查可以帮助开发者提高源字符串的质量。
省略号#
- 概要:
这条字符串使用三个句点 (…) 代替了省略号 (…)
- 范围:
源字符串
- 检查的类:
weblate.checks.source.EllipsisCheck- 检查的标识符:
ellipsis- 忽略的标记:
ignore-ellipsis
当字符串使用三个点 (...) ,而它应该使用一个省略号字符 (…),时就会失败。
在大多数情况下,使用 Unicode 字符是更好的方法,并且看起来呈现得更好,并且使用文本到语音转换可能听起来更好。
ICU MessageFormat 语法#
在 4.9 版本加入.
- 概要:
ICU MessageFormat 字符串中的语法错误。
- 范围:
源字符串
- 检查的类:
weblate.checks.icu.ICUSourceCheck- 检查的标识符:
icu_message_format_syntax- 启用的标记:
icu-message-format- 忽略的标记:
ignore-icu-message-format
长期未翻译#
在 4.1 版本加入.
- 概要:
这条字符串已经很长时间未被翻译了
- 范围:
源字符串
- 检查的类:
weblate.checks.source.LongUntranslatedCheck- 检查的标识符:
long_untranslated- 忽略的标记:
ignore-long-untranslated
当字符串很长时间没有被翻译时,它可能表明源字符串中存在问题,使其难以翻译。
多项未通过的检查#
- 概要:
多种语言的译文都有未通过的检查
- 范围:
源字符串
- 检查的类:
weblate.checks.source.MultipleFailingCheck- 检查的标识符:
multiple_failures- 忽略的标记:
ignore-multiple-failures
该字符串的许多翻译都未通过质量检查。这通常表明可以采取一些措施来改进源字符串。
这种检查失败往往是由于句子末尾缺少句号或类似的小问题造成的,译者往往在译文中解决这些问题,而最好在源字符串中解决。
多个未命名的变量#
在 4.1 版本加入.
- 概要:
字符串中有多个未命名的变量,因此译者无法重新排序它们
- 范围:
源字符串
- 检查的类:
weblate.checks.format.MultipleUnnamedFormatsCheck- 检查的标识符:
unnamed_format- 忽略的标记:
ignore-unnamed-format
字符串中有多个未命名的变量,因此译者无法重新排序它们。
考虑使用命名变量来允许翻译人员重新排序。
未复数化#
- 概要:
这条字符串应该用作复数,但未使用其复数形式
- 范围:
源字符串
- 检查的类:
weblate.checks.source.OptionalPluralCheck- 检查的标识符:
optional_plural- 忽略的标记:
ignore-optional-plural
字符串用作复数形式,但不使用复数形式。如果您的翻译系统支持此功能,则应使用它的复数感知变体。
例如,在Python中使用Gettext,它可以是:
from gettext import ngettext
print(ngettext("Selected %d file", "Selected %d files", files) % files)