翻訳者コミュニティの構築
下記の機能を適切に設定することにより、多言語による完全な機械翻訳後編集に対応できます。良い翻訳は、文脈的に正しい翻訳を目指す House のシステム機能モデルにより定義されます。独自の 機械翻訳後編集のガイドライン を作成し、独自の定義に合わせてこれらの推奨事項を変更します。多くの場合、ブラウザー プラグインの言語ツール は、機械翻訳後編集の校正ツールとして使用できます。
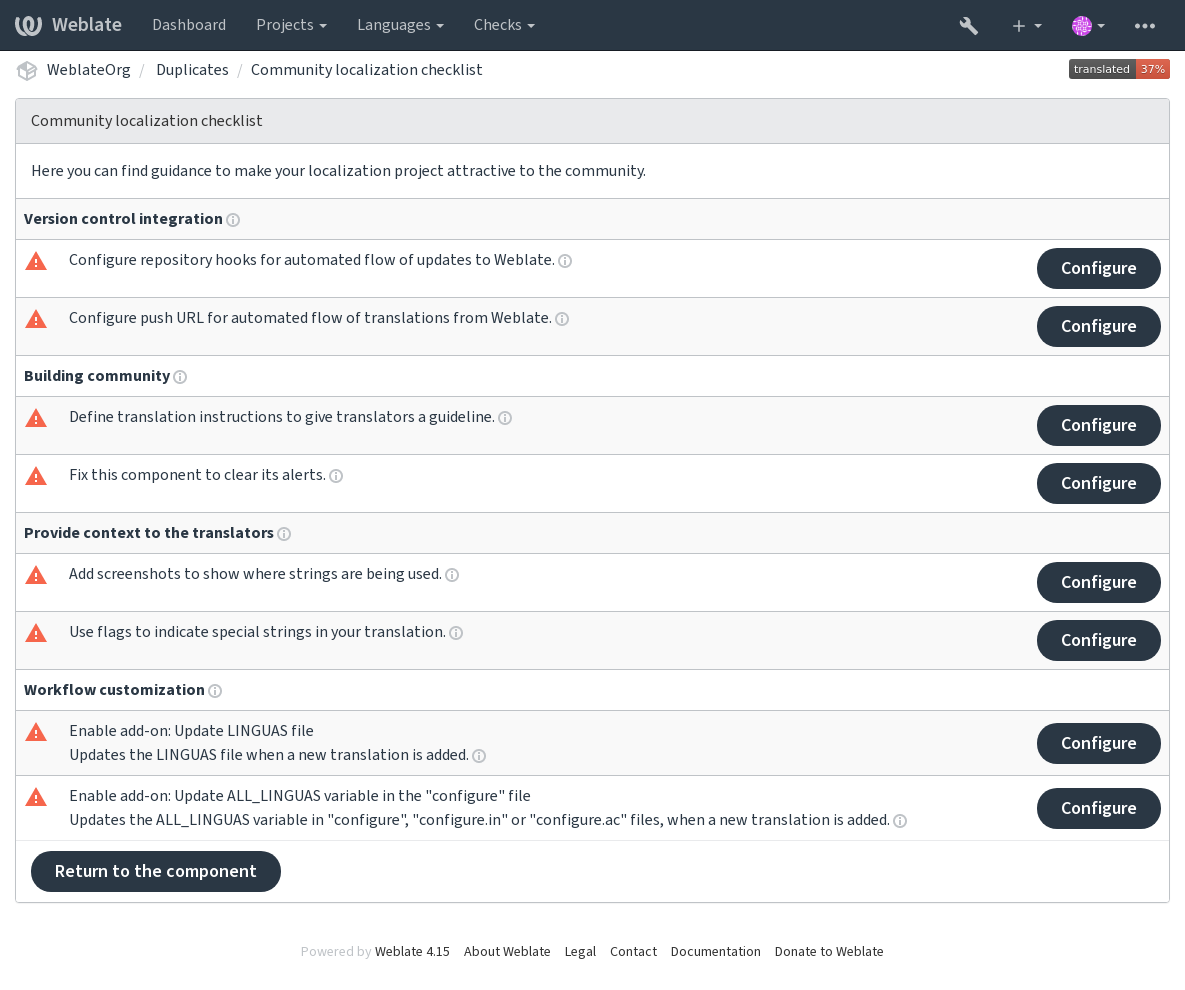
現地化コミュニティのチェックリスト
バージョン 3.9 で追加.
各コンポーネントのメニューに記載されている 現地化コミュニティのチェックリスト を使用すると、現地語化の作業をコミュニティの翻訳者が簡単に行うためのガイダンスを提供します。
用語集の管理
用語の割り当てを使用した機械翻訳後の編集は、翻訳プロセスの各レベルに影響を与えます。機械翻訳システムは、継続的なトレーニングまたは ニューラル ファジー修復 を使用して、特定の語彙と文例に適合させます。既存の翻訳メモリを weblate に インポート するか、基本的な用語を含む初期の用語集を作成します。最終的には、その分野における経験と知識に基づく結果を保証するために、専門家に頼んで追加の用語集を作成してください。
機械翻訳
自動翻訳(多くの場合、BLEU スコアで測定)の品質は、翻訳時間と相関関係があります [1] 。必要な言語とドメインに対応するマシンのバックエンドを選択します。翻訳バックエンドの仕組みを理解し、機械翻訳後の人間による編集者が必要とする品質を明確にします。
翻訳の査読
翻訳は、機械翻訳後の編集を誰かがしたあとに、別の人が査読することが重要です。公平で有能な校閲者がいることにより、2 人体制のもとで、誤訳が減少し、翻訳の品質と一貫性を保てます。
構造化されたフィードバック
Weblate には、翻訳の品質を行う構造化されたフィードバックを実現する多くの 検査と修正 があります。
翻訳の定義
テキストに基づく言語的アプローチは、精神的および効果に基づく定義を大幅に削減する可能性だけでなく、組み込みの翻訳手法として最適です。翻訳評価のための十分に定式化された理論は、オリジナルと翻訳の関係に焦点を当てた House の体系的機能モデルです。このモデルでは、翻訳とは、ある言語コードから別の言語コードに移行するときに、テキストの意味、語用論、およびテキストの意味を同等に保つ試みであると想定しています。
翻訳の品質は、機械翻訳が文字列情報をどの程度理解できるかにかかっています。結果は予測できないため、機械が正確に理解できるように人間が十分な情報を与えることが必要です。機械翻訳が理解するために主に必要な 2 つのパラメータは、マクロ情報(全体の関連性と具体的な意味の内包が必要)および、分野、趣旨、手段からなる細かい状況説明です。
原文
Marina Sanchez-Torron と Philipp Koehn、機械翻訳の品質と編集後の生産性。図 1: https://www.cs.jhu.edu/~phi/publications/machine-translation-quality.pdf
Joanna Best と Sylvia Kalina。翻訳と通訳: オリエンテーションのヘルプ。 A. Francke Verlag Tübingen と Base、2002 年。翻訳批評の機会 p.101 頁 以降
ニューラル ファジー修復。Bram Bulté と Arda Tezcan、ニューラル ファジー修復: あいまい一致のニューラル機械翻訳への統合、2019 年。https://aclanthology.org/P19-1175.pdf