检查和修正¶
定制的自动修正¶
还可以应用除了自动修正以外自己的自动修正,并将它们包括到 AUTOFIX_LIST。
自动修复很强大,但可能导致损坏;写脚本的时候要小心。
例如,后面的自动修复会将每次出现的字符串 foo 在翻译中替换为 bar:
from weblate.trans.autofixes.base import AutoFix
class ReplaceFooWithBar(AutoFix):
"""Replace foo with bar."""
# Might be localized using gettext_lazy
name = "Foobar"
def fix_single_target(self, target, source, unit):
if "foo" in target:
return target.replace("foo", "bar"), True
return target, False
为了安装定制的检查,在 AUTOFIX_LIST 中为 Python 类提供完全合规的路径,请参见 定制的质量检查、附加组件、自动建议和自动修复。
使用标记定制行为¶
您可以使用标记微调 Weblate 的行为。标记向译者提供视觉反馈并帮助译者改进翻译。标记是从下列源合并的:
源字符串附加标记:
从文件格式提取的每字符串标记,见 本地化文件格式。
翻译标记(当前仅双语源字符串的
read-only标记或当单语言模板编辑关闭时)。文件格式特定的标记。
标记用逗号分隔,如果有参数的话,则用冒号分隔。可以在字符串中使用引号来包含空格字符或特定字符。例如:
placeholders:"special:value":"other value", regex:.*
单引号和双引号都被接受,特殊字符使用反斜杠进行转义:
placeholders:"quoted \"string\"":'single \'quoted\''
placeholders:r"^#*"
为了验证译者没有更改 Markdown 文档的标题。如果字符串 ### Index 被译作 # Indice,会触发失败的检查。
placeholders:r"\]\([^h].*?\)"
为了确保不翻译内部链接(即 [test](../checks) 不变成 [test](../chequeos).
可以用 discard:NAME 语法忽略更高层级定义的标记。比如,如果部件配置为 safe-html,你可以添加 discard:safe-html 到字符串标记让这个特定字符串跳过它。
以下是目前接受的标记列表:
read-only这条字符串是只读的,且不应该在 Weblate 中进行编辑。请参见 只读字符串。
terminology用在 术语表。将字符串复制进所有术语表语言,以便在所有翻译中使用相同表述。和
read-only搭配用在产品名等地方也有用。priority:N字符串的优先级。高优先级的字符串首先出现被翻译。默认的优先级是 100,字符串的优先级越高,就会越早安排翻译。
max-length:N将字符串的最大长度限制为 N 个字符,请参见 译文最大长度。
xml-textfont-family:NAME定义 font-family 来提供检查,请参见 管理字型。
font-weight:WEIGHT定义 font-weight 来提供检查,请参见 管理字型。
font-size:SIZE定义 font-size 来提供检查,请参见 管理字型。
font-spacing:SPACING定义渲染检查的字母间隔,请参见 管理字型。
icu-flags:FLAGS指定自定义 ICU MessageFormat 质量检查行为的标记。
icu-tag-prefix:PREFIX为 ICU MessageFormat 质量检查设置必需的 XML 标签前缀。
placeholders:NAME:NAME2:...译文中需要的占位符字符串,请参见 占位符。
replacements:FROM:TO:FROM2:TO2...当检查结果文本参数时执行替换(例如在 译文最大尺寸 或 译文最大长度 中)。这一典型应用的情况拓展了非译元素,确保匹配那些即使使用了长值的文本,例如
replacements:%s:"John Doe"。variants:SOURCE将此字符串标记为具有匹配源的字符串的变体。见 字符串变体。
regex:REGEX用于匹配翻译文件的正则表达式,详见 正则表达式。
discard:NAME丢弃在更高级别定义的标记。
forbidden表示术语表中禁止的译文,参见 禁止的译文。
strict-same让 未更改的译文 避免使用内置的不使用的单词。
strict-format让格式检查强制使用格式,即使对单一值的复数形式也是如此,见 格式化字符串。
case-insensitive调整检查行为不区分大小写。目前仅影响 占位符 质量检查。
acceleratorSpecify the single punctuation accelerator marker, for example
accelerator:&,accelerator:_, oraccelerator:~. Enables the 加速器键 quality check.bbcode-text将文本视为 Bulletin Board Code(BBCode)文档,影响 未更改的译文。启用 BBCode 标记 质量检查。
check-glossary启用 不遵循术语表 质量检查。
fluent-parts启用 Fluent 部分 质量检查。
fluent-references启用 Fluent 参考 质量检查。
fluent-target-inner-html启用 Fluent 翻译内部 HTML 质量检查。
fluent-target-syntax启用 Fluent 翻译语法 质量检查。
angularjs-format启用 AngularJS 插值字符串 质量检查。
automattic-components-format启用 Automattic 部件格式化 质量检查。
c-format启用 C 格式 质量检查。
c-sharp-format启用 C# 格式 质量检查。
csharp-format启用 C# 格式 质量检查。
es-format启用 ECMAScript 模板字面量 质量检查。
i18next-interpolation启用 i18next 插值 质量检查。
icu-message-format启用 ICU MessageFormat 和 ICU MessageFormat 语法 质量检查。
java-printf-format启用 Java 格式 质量检查。
java-format启用 Java MessageFormat 质量检查。
auto-java-messageformat将文本视为有条件的 Java MessageFormat,只在原文包含 Java MessageFormat 占位符时启用 Java MessageFormat。启用 Java MessageFormat 质量检查。
javascript-format启用 JavaScript 格式 质量检查。
laravel-format启用 Laravel 格式 质量检查。
lua-format启用 Lua 格式 质量检查。
object-pascal-format启用 Object Pascal 格式 质量检查。
objc-format启用 Objective-C 格式 质量检查。
percent-placeholders启用 百分比占位符 质量检查。
perl-brace-format启用 Perl brace 格式 质量检查。
perl-format启用 Perl 格式 质量检查。
php-format启用 PHP 格式 质量检查。
python-brace-format启用 Python brace 格式 质量检查。
python-format启用 Python 格式 质量检查。
qt-format启用 Qt 格式 质量检查。
qt-plural-format启用 Qt 复数格式 质量检查。
ruby-format启用 Ruby 格式 质量检查。
scheme-format启用 Scheme 格式 质量检查。
vue-format启用 Vue I18n 格式化 质量检查。
rst-text将文本视为 reStructuredText 文档,影响 未更改的译文。启用 reStructuredText 不一致 和 reStructuredText 语法错误 质量检查。
md-text将文本视为 Markdown 文档,并在翻译文本区域提供 Markdown 语法高亮。启用 Markdown 链接、Markdown 引用 和 Markdown 语法 质量检查。
max-length启用 译文最大长度 质量检查。
max-size启用 译文最大尺寸 质量检查。
placeholders启用 占位符 质量检查。
regex启用 正则表达式 质量检查。
safe-mdx启用 安全的 MDX 质量检查。
safe-html启用 不安全的 HTML 质量检查。
auto-safe-html将文本视作有条件的 HTML,只对纯文本或包含标准 HTML 记号或有效自定义元素的源字符串启用 不安全的 HTML。这对 MDX 等扩展的 Markdown 变体有用,在这些变体中尖括号语法可能不是 HTML。启用 不安全的 HTML 质量检查。
url字符串应该只由一个 URL 组成。启用 URL 质量检查。
fluent-source-inner-html启用 Fluent 源内部 HTML 质量检查。
fluent-source-syntax启用 Fluent 源语法 质量检查。
ignore-all-checks忽略所有质量检查。
ignore-accelerator跳过 加速器键 质量检查。
ignore-bbcode跳过 BBCode 标记 质量检查。
ignore-xml-chars-around-tags跳过 XML 标签周围的字符 质量检查。
ignore-duplicate跳过 连续重复的单词 质量检查。
ignore-check-glossary跳过 不遵循术语表 质量检查。
ignore-double-space跳过 双空格 质量检查。
ignore-fluent-parts跳过 Fluent 部分 质量检查。
ignore-fluent-references跳过 Fluent 参考 质量检查。
ignore-fluent-target-inner-html跳过 Fluent 翻译内部 HTML 质量检查。
ignore-fluent-target-syntax跳过 Fluent 翻译语法 质量检查。
ignore-angularjs-format跳过 AngularJS 插值字符串 质量检查。
ignore-automattic-components-format跳过 Automattic 部件格式化 质量检查。
ignore-c-format跳过 C 格式 质量检查。
ignore-c-sharp-format跳过 C# 格式 质量检查。
ignore-es-format跳过 ECMAScript 模板字面量 质量检查。
ignore-i18next-interpolation跳过 i18next 插值 质量检查。
ignore-icu-message-format跳过 ICU MessageFormat 质量检查。
ignore-java-printf-format跳过 Java 格式 质量检查。
ignore-java-format跳过 Java MessageFormat 质量检查。
ignore-javascript-format跳过 JavaScript 格式 质量检查。
ignore-laravel-format跳过 Laravel 格式 质量检查。
ignore-lua-format跳过 Lua 格式 质量检查。
ignore-object-pascal-format跳过 Object Pascal 格式 质量检查。
ignore-objc-format跳过 Objective-C 格式 质量检查。
ignore-percent-placeholders跳过 百分比占位符 质量检查。
ignore-perl-brace-format跳过 Perl brace 格式 质量检查。
ignore-perl-format跳过 Perl 格式 质量检查。
ignore-php-format跳过 PHP 格式 质量检查。
ignore-python-brace-format跳过 Python brace 格式 质量检查。
ignore-python-format跳过 Python 格式 质量检查。
ignore-qt-format跳过 Qt 格式 质量检查。
ignore-qt-plural-format跳过 Qt 复数格式 质量检查。
ignore-ruby-format跳过 Ruby 格式 质量检查。
ignore-scheme-format跳过 Scheme 格式 质量检查。
ignore-vue-format跳过 Vue I18n 格式化 质量检查。
ignore-translated跳过 曾被翻译过 质量检查。
ignore-inconsistent跳过 不一致的 质量检查。
ignore-rst-references跳过 reStructuredText 不一致 质量检查。
ignore-kashida跳过 使用了 Kashida 字母 质量检查。
ignore-md-link跳过 Markdown 链接 质量检查。
ignore-md-reflink跳过 Markdown 引用 质量检查。
ignore-md-syntax跳过 Markdown 语法 质量检查。
ignore-max-length跳过 译文最大长度 质量检查。
ignore-max-size跳过 译文最大尺寸 质量检查。
ignore-escaped-newline跳过 不匹配的 \n 质量检查。
ignore-end-colon跳过 不匹配的冒号 质量检查。
ignore-end-ellipsis跳过 不匹配的省略号 质量检查。
ignore-end-exclamation跳过 不匹配的感叹号 质量检查。
ignore-end-stop跳过 不匹配的句号 质量检查。
ignore-end-interrobang跳过 不匹配的疑问惊叹号 质量检查。
ignore-end-question跳过 不匹配的问号 质量检查。
ignore-end-semicolon跳过 不匹配的分号 质量检查。
ignore-newline-count跳过 不匹配的换行符 质量检查。
ignore-plurals跳过 缺少复数形式 质量检查。
ignore-multiple-capital跳过 多个大写字母 质量检查。
ignore-kabyle-characters跳过 卡拜尔语中的非标准字符 质量检查。
ignore-placeholders跳过 占位符 质量检查。
ignore-prohibited-initial-character跳过 禁止的初始字符 质量检查。
ignore-punctuation-spacing跳过 标点间距 质量检查。
ignore-regex跳过 正则表达式 质量检查。
ignore-rst-syntax跳过 reStructuredText 语法错误 质量检查。
ignore-reused跳过 重用的译文 质量检查。
ignore-safe-mdx跳过 安全的 MDX 质量检查。
ignore-same-plurals跳过 相同的复数形式 质量检查。
ignore-begin-newline跳过 换行符开头 质量检查。
ignore-begin-space跳过 空格开头 质量检查。
ignore-end-newline跳过 换行符结尾 质量检查。
ignore-end-space跳过 空格结尾 质量检查。
ignore-same跳过 未更改的译文 质量检查。
ignore-safe-html跳过 不安全的 HTML 质量检查。
ignore-url跳过 URL 质量检查。
ignore-xml-tags跳过 XML 标记 质量检查。
ignore-xml-invalid跳过 XML 语法 质量检查。
ignore-zero-width-space跳过 零宽空格 质量检查。
ignore-ellipsis跳过 省略号 质量检查。
ignore-fluent-source-inner-html跳过 Fluent 源内部 HTML 质量检查。
ignore-fluent-source-syntax跳过 Fluent 源语法 质量检查。
ignore-icu-message-format跳过 ICU MessageFormat 语法 质量检查。
ignore-long-untranslated跳过 长期未翻译 质量检查。
ignore-multiple-failures跳过 多项未通过的检查 质量检查。
ignore-unnamed-format跳过 多个未命名的变量 质量检查。
ignore-source-max-length跳过 源字符串长度 质量检查。
ignore-optional-plural跳过 未复数化 质量检查。
备注
通常,对于任何检查,都可以使用标识符将规则命名为 ignore-*,所以您甚至可以将其用于自定义检查。
每个源字符串的设置,在 部件配置 设置中,并且在翻译文件自身中(例如在 GNU gettex 中),能够理解这些标记。
基于位置的标记¶
根据它们的位置,一些标记被默认添加到字符串。这表示根据使用字符串的地方,某些检查将被自动开启。
rst-text:该标记被自动添加到 reStructuredText 文件中的字符串,如果位置扩展名是.rst.md-text: 该标记被自动添加到 Markdown 和 MDX 文件中的字符串,如果位置扩展名是.md、.markdown或.mdx。
强制检查¶
强制检查不能被忽略并会把字符串标记为 Needs editing (见 翻译状态)。这防止译者隐藏这样的检查。
提示
启用检查强制不会自动启用它。一些检查必需开启,方法是将相应的标记添加到字符串或部件标记。
对 格式化字符串 等最适宜使用它,不检查这些可能造成严重问题。不建议用它进行 未更改的译文 等样式检查,因为在这些情景下忽略有时是合理的方法。
然后可以用 翻译质量筛选器 来从提交到版本控制的字符串中排除需要编辑的字符串。
管理字型¶
提示
上传到 Weblate 的字体仅用于 译文最大尺寸 检查,它们对 Weblate 用户界面没有影响。
用于计算所呈现文本尺寸的 译文最大尺寸 检查需要将字体加载到 Weblate 中,并使用翻译标记选中(请参见 使用标记定制行为)。
在您的翻译项目 操作 菜单下 字体 中的 Weblate 字体管理工具提供了上传和管理字体的界面。可以上传 TrueType 或 OpenType 字体,设置 font-groups 并在检查中使用它们。
字型组允许为不同语言确定不同字型,这是非拉丁语言中典型需要的:
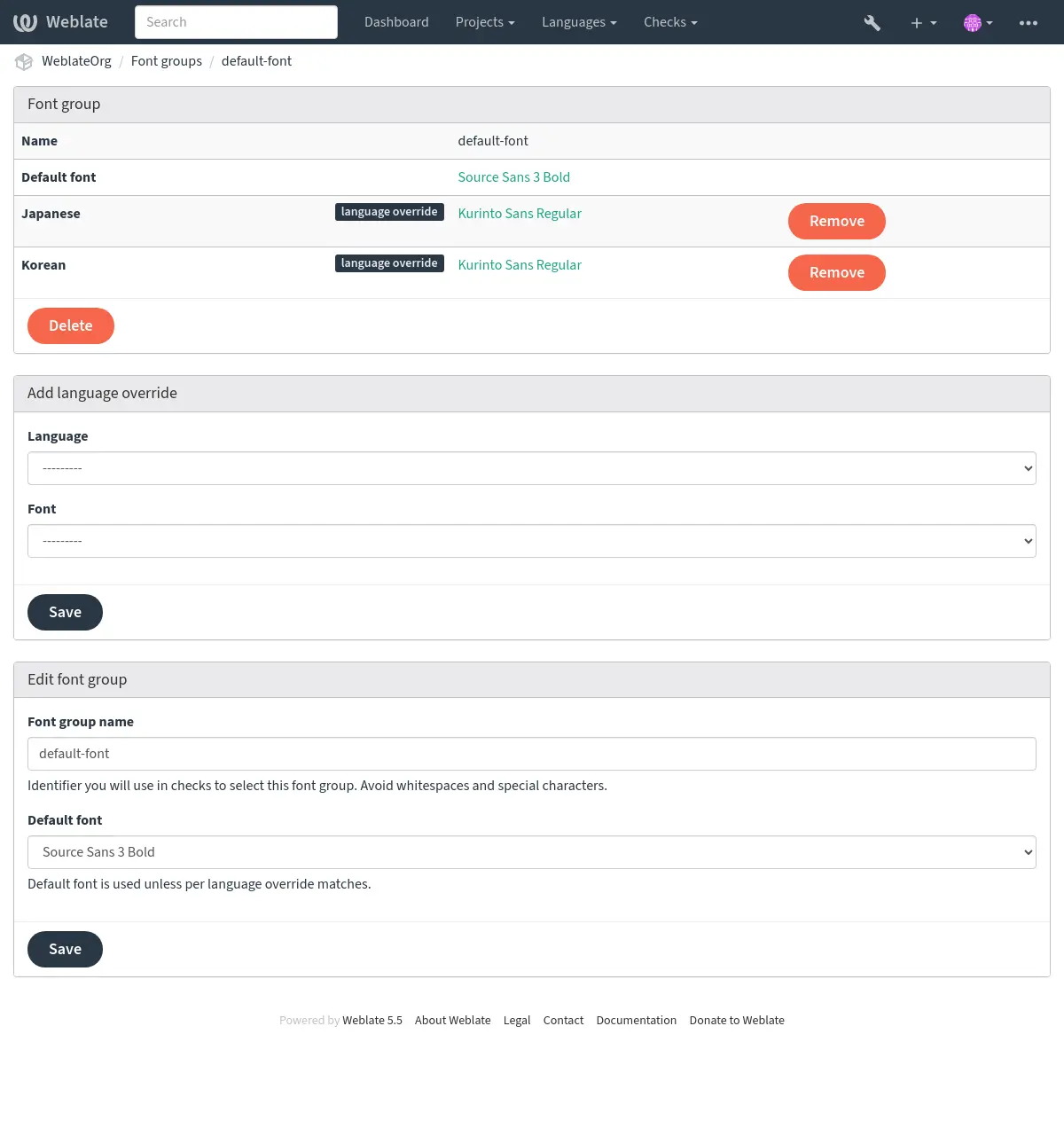
字型组通过名称识别,名称不能包含空格或特殊字符,这使它能够容易地用在检查定义中:
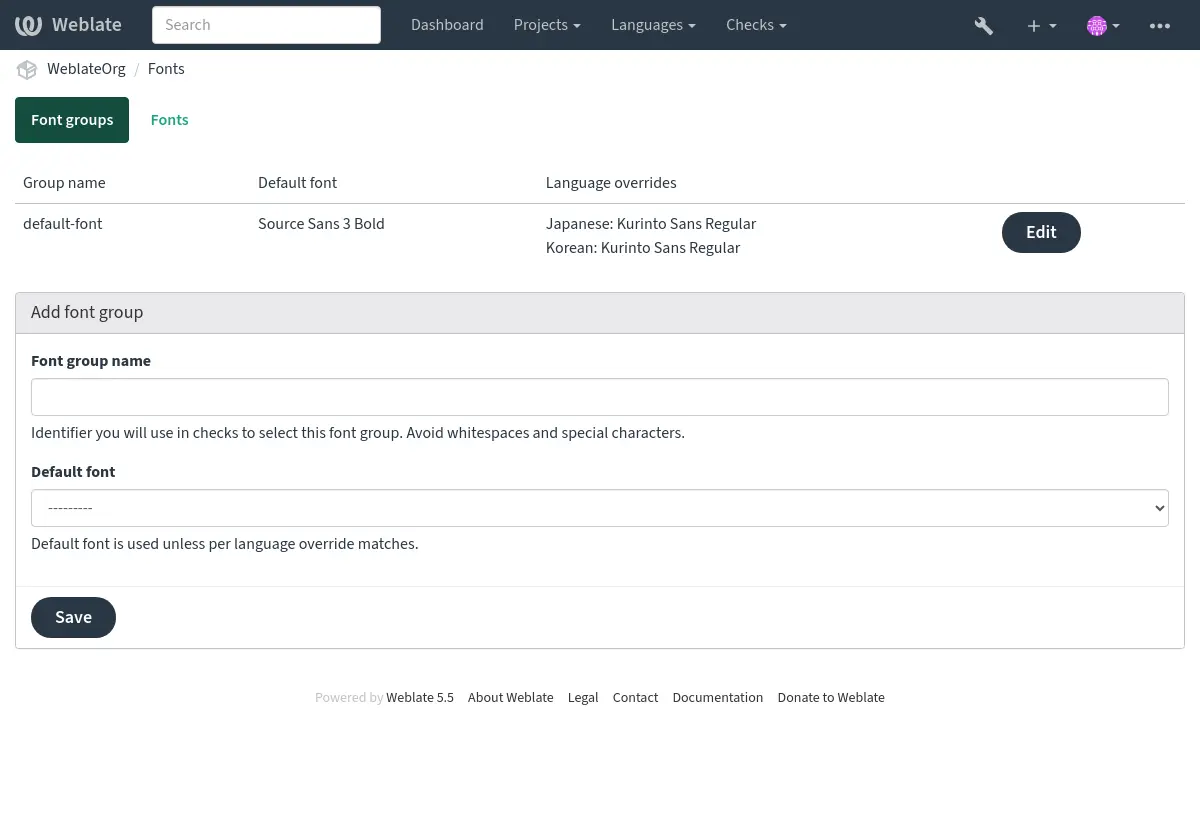
字型族和样式在上传后自动识别:

可以将几种字型加载到 Weblate 中:
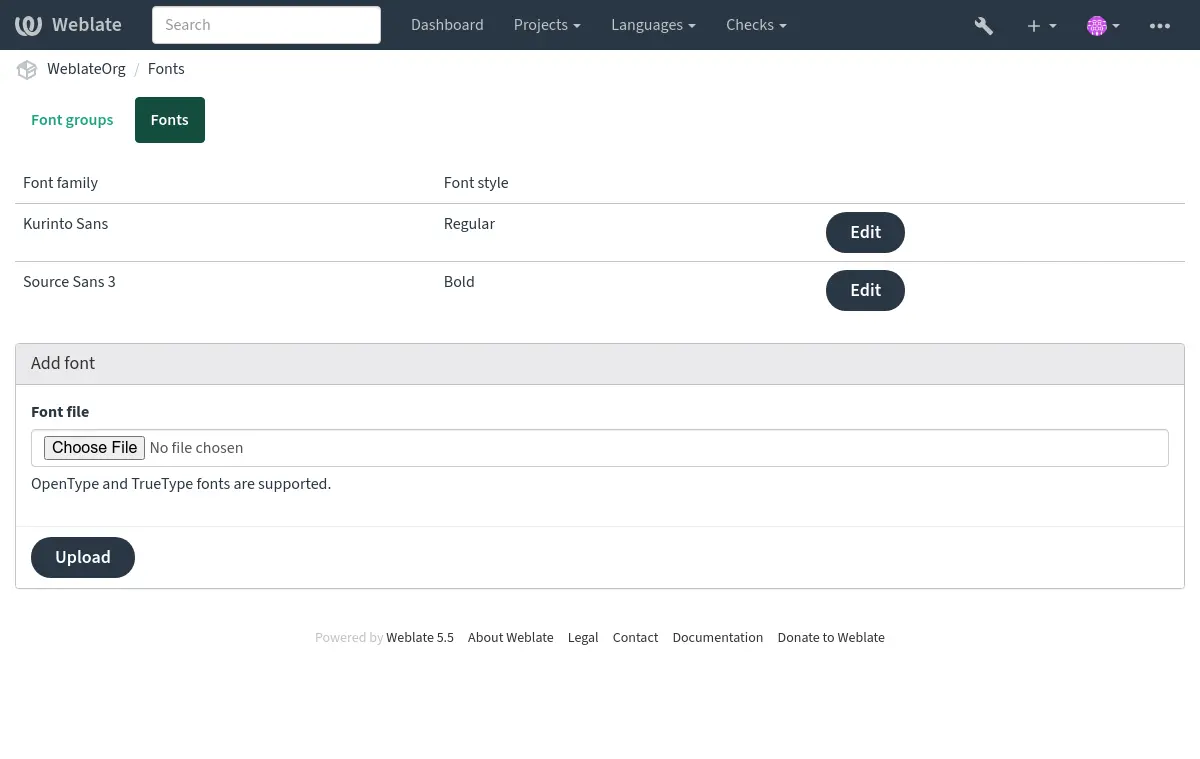
为了使用字型来检查字符串长度,将适当的标记传递给它(请参见 使用标记定制行为)。可能会需要后面这些:
max-size:500/max-size:300:5定义宽度的最高像素,以及最大行数u。配置了超过一行时应用换行操作。
font-family:ubuntu通过指定其标识符来定义要使用的字型组。
font-size:22指定以像素为单位的字体大小。
编写自己的检查¶
Weblate 内置了多种多样的质量检查,(请参阅 质量检查),尽管它们可能没有涵盖您想要检查的所有东西。可以使用 CHECK_LIST 来调整执行的检查列表,也可以添加自定义检查。
子类 weblate.checks.Check
设置一些属性。
应用
check(如果想要处理代码中的复数的话)或check_single方法(它将为你完成)。
一些示例:
为了安装定制的检查,在 CHECK_LIST 中为 Python 类提供完全合格的路径,请参见 定制的质量检查、附加组件、自动建议和自动修复。
检查译文文本是否不包含“foo”¶
这是一个非常简单的检查,只是检查译文中是否缺少了字符串“foo”。
"""Simple quality check example."""
from django.utils.translation import gettext_lazy
from weblate.checks.base import TargetCheck
class FooCheck(TargetCheck):
# Used as identifier for check, should be unique
# Has to be shorter than 50 characters
check_id = "foo"
# Short name used to display failing check
# Might be localized using gettext_lazy
name = "Foo check"
# Description for failing check
description = gettext_lazy("Your translation is foo")
# Real check code
def check_single(self, source, target, unit):
return "foo" in target
检查捷克语译文文本复数是否不同¶
使用语言信息检查,验证捷克语中的两种复数形式不同。
"""Quality check example for Czech plurals."""
from django.utils.translation import gettext_lazy
from weblate.checks.base import TargetCheck
class PluralCzechCheck(TargetCheck):
# Used as identifier for check, should be unique
# Has to be shorter than 50 characters
check_id = "foo"
# Short name used to display failing check
# Might be localized using gettext_lazy
name = "Foo check"
# Description for failing check
description = gettext_lazy("Your translation is foo")
# Real check code
def check_target_unit(self, sources, targets, unit):
if unit.translation.language.is_base({"cs"}):
return targets[1] == targets[2]
return False
def check_single(self, source, target, unit) -> bool:
"""We don't check target strings here."""
return False