検査と修正¶
The quality checks help catch common translator errors, ensuring the translation is in good shape. The checks can be ignored in case of false positives. For practical translation guidance around placeholders, markup, punctuation, and plural forms, see Translating special text safely.
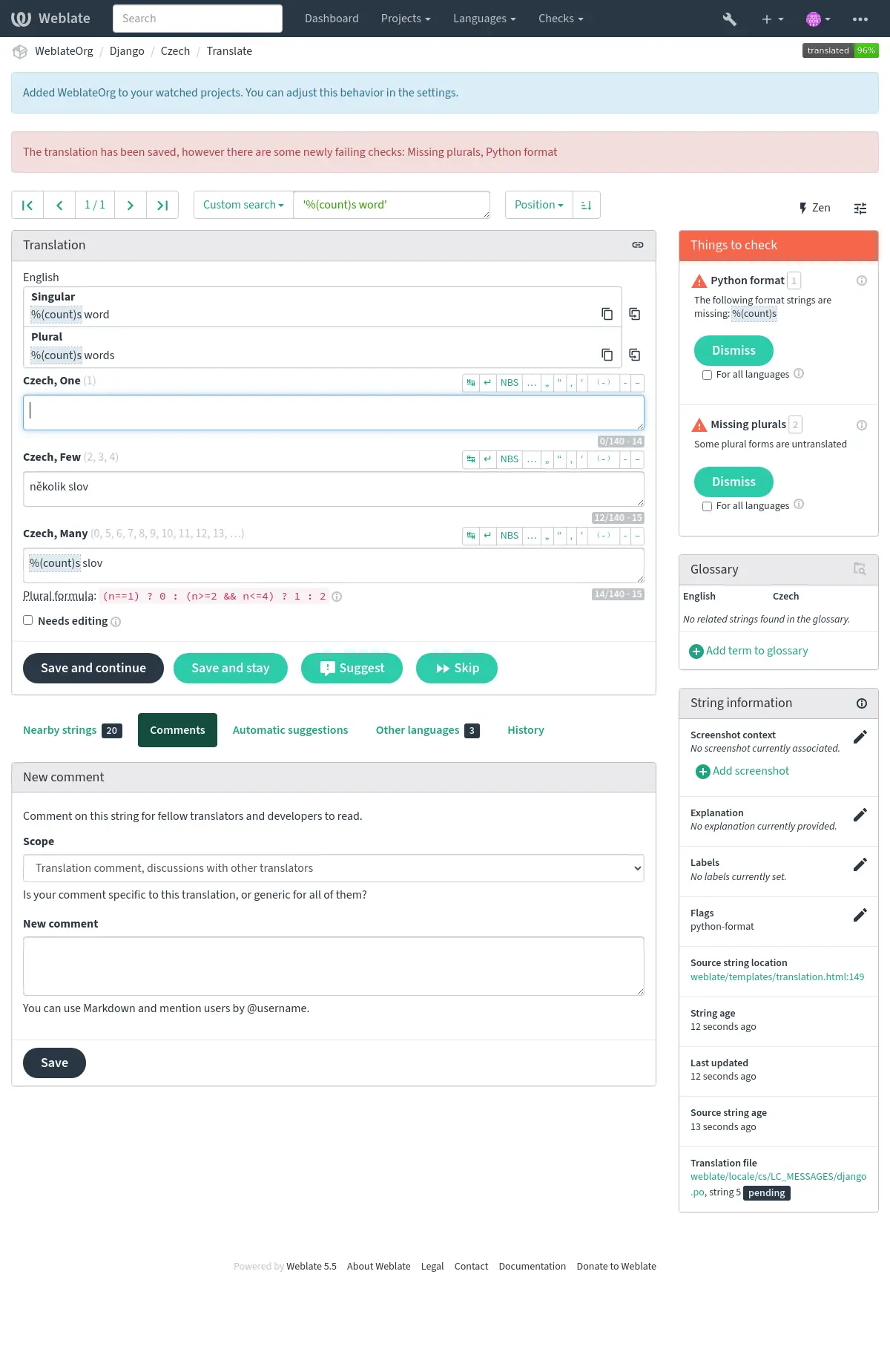
保存した翻訳が検査で不合格となった場合に、すぐにユーザーに警告を表示します。表示例:
自動修正¶
品質検査 に加えて、Weblate は翻訳した文字列の一般的な翻訳ミスを自動的に修正できます。翻訳ミスを誘発しないよう設定には注意をしてください。
参考
文末の省略記号の置き換え¶
- クラス名:
weblate.trans.autofixes.chars.ReplaceTrailingDotsWithEllipsis
原文と一致するように、末尾のドット(...)を省略記号(…)に置き換えます。
ゼロ幅スペースの削除¶
- クラス名:
weblate.trans.autofixes.chars.RemoveZeroSpace
通常、ゼロ幅のスペースは、翻訳には不要です。この修正により、原文の文字列にも存在しない限り、ゼロ幅のスペースが削除されます。
制御文字の削除¶
- クラス名:
weblate.trans.autofixes.chars.RemoveControlChars
原文に制御文字が含まれていない場合は、制御文字を削除する。
デーヴァナーガリー文字のダンダ句読点¶
- クラス名:
weblate.trans.autofixes.chars.DevanagariDanda
ベンガル語の文末のピリオドを、デーヴァナーガリーのダンダ記号(।)に置き換えます。
句読点のスペース¶
- クラス名:
weblate.trans.autofixes.chars.PunctuationSpacing
Added in version 5.3.
フランス語で正しい句読点間隔が使用されるようにしました。
この修正は ignore-punctuation-spacing フラグで無効にできます(これにより 句読点のスペース も無効になる)。
安全でない HTML のクリーンアップ¶
- クラス名:
weblate.trans.autofixes.html.BleachHTML
safe-html のフラグが付いた文字列から安全でない HTML マークアップを削除。
参考
文頭と文末の空白の修正¶
- クラス名:
weblate.trans.autofixes.whitespace.SameBookendingWhitespace
先頭と末尾の空白を原文と一致させます。 ignore-begin-space および ignore-end-space フラグを使用して、処理の一部を省略するように調整できます。
品質検査¶
Weblate では、文字列に対してさまざまな品質検査をしています。次のセクションでは、すべての検査項目について詳しく説明します。言語固有の検査もあります。誤検出が起こる場合はバグを報告してください。
翻訳時の検査¶
翻訳文を変更するたびに検査をするため、翻訳者は高品質な翻訳を維持できます。
Accelerator key¶
Added in version 2026.7.
- 概要:
Source and translation contain inconsistent accelerator keys.
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.AcceleratorKeyCheck- 検査の識別子:
accelerator- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
accelerator- 除外フラグ:
ignore-accelerator
Accelerator keys (also known as mnemonics) let users trigger a UI action from
the keyboard. They are marked in the string by a single punctuation character,
typically & (Qt, Windows), _ (GTK), or ~. Literal marker characters
can usually be escaped by doubling them, and are ignored by this check. Enable
this check with the accelerator: flag to explicitly choose the marker, for
example accelerator:&, accelerator:_, or accelerator:~.
This check verifies that the source and the translation contain the same number of accelerator keys, and that the translation does not contain more than one.
注釈
A string such as Walter & Sons might be translated without the
ampersand and trigger a false positive. Use the ignore-accelerator
flag to skip the check for such strings.
BBCode マークアップ¶
バージョン 5.10 で変更: この検査は、信頼性の低い自動検出には依存しなくなりました。現在は bbcode-text フラグを使用して有効化してください。
- 概要:
翻訳文の BBCode が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.BBCodeCheck- 検査の識別子:
bbcode- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
bbcode-text- 除外フラグ:
ignore-bbcode
BBCode は、メッセージの重要な部分を太字フォントや斜体で強調するなどの表示を、単純なマークアップで記述します。
この検査は、BBCode が翻訳文にも含まれているかどうかを確認します。
注釈
現在、BBCode を検出する方法は非常に単純であり、この検査では誤検知が発生することがあります。
重複単語の連続¶
Added in version 4.1.
- 概要:
翻訳文で同じ単語が 2 回連続した文字列。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.duplicate.DuplicateCheck- 検査の識別子:
duplicate- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-duplicate
翻訳文に重複する単語が連続してないか検査します。通常は、翻訳ミスです。
ヒント
この検査には、誤検出を避けるための言語固有の規則が含まれています。お客様のケースで誤作動した場合はお知らせください。参照: Weblate の問題の報告。
用語集に従っていない¶
Added in version 4.5.
- 概要:
翻訳文は用語集に定義された用語に従っていない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.glossary.GlossaryCheck- 検査の識別子:
check_glossary- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
check-glossary- 除外フラグ:
ignore-check-glossary
この検査は、check-glossary フラグを使用して有効にします(参照: フラグを使用した動作の設定)。有効にする前に、考慮が必要な項目:
完全一致で文字列の照合をします。用語集には、用語の別表記はすべて含まれていることが前提です。
各文字列を用語集と照合して検査するのは大変な作業です。文字列のインポートや翻訳など、検査を引き起こす Weblate のすべての操作が遅くなります。
また、未翻訳の翻訳文 では用語集の翻訳禁止の用語も活用します。
連続スペース¶
- 概要:
翻訳文に連続したスペースが含まれている。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.DoubleSpaceCheck- 検査の識別子:
double_space- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-double-space
翻訳文の中でスペースが連続しているかどうかを検査し、ほかのスペース関連の検査での誤検出を防ぎます。
原文に連続したスペースがある場合は、意図的なものなので検査で不合格になりません。
Fluent パーツ¶
Added in version 5.0.
- 概要:
Fluent パーツは一致することが必要です。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.fluent.parts.FluentPartsCheck- 検査の識別子:
fluent-parts- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-parts- 除外フラグ:
ignore-fluent-parts
各 Fluent メッセージにはオプションの値(メインのテキストコンテンツ)とオプションの属性が含まれ、それぞれがメッセージの「部分」です。Weblate では、これらのすべての部分が同じブロック内に表示され、属性を指定するために Fluent 風の構文が使用されます。例:
This is the Message value
.title = This is the title attribute
.alt = This is the alt attribute
この検査は、原文のメッセージに値がある場合は翻訳されたメッセージにも値があること、原文のメッセージに値がない場合は翻訳にも値がないことを確認します。また、原文のメッセージで使われている属性が翻訳にもあり、他に属性が追加されていないかも確認します。
注釈
この検査は Fluent 用語には適用されません。なぜなら、用語は常に値を持つためです。また、用語の属性はロケール固有のものであり(文法規則などで使用)、すべての翻訳に表示されることは期待されないからです。
参考
Fluent 参照¶
Added in version 5.0.
- 概要:
Fluent 参照は一致することが必要です。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.fluent.references.FluentReferencesCheck- 検査の識別子:
fluent-references- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-references- 除外フラグ:
ignore-fluent-references
Fluent メッセージや用語は、他のメッセージ、用語、属性、または変数を参照できます。例:
Here is a { message }, a { message.attribute } a { -term } and a { $variable }.
Within a function { NUMBER($num, minimumFractionDigits: 2) }
一般的に、翻訳されたメッセージや用語には、ソースと同じ参照が含まれていることが求められます。ただし、必ずしも同じ順序で表示されることは必要ありません。したがって、この検査は翻訳がソースの値と同じ参照を使用し、同じ回数、追加なしで使用していることを確認します。メッセージの場合、翻訳の各属性が、ソースの対応する属性と同じ参照を使用していることも確認します。
ソースまたは翻訳に Fluent Select 式が含まれている場合、ソースの各可能な別表記の文字列は、翻訳においても同じ参照を持つ少なくとも 1 つの別表記の文字列と一致することが必要であり、その逆も同様です。
さらに、もし変数参照が選択式のセレクタ内とその別表記の文字列の 1 つ内の両方に現れる場合、その場合すべての別表記の文字列もその参照を含むかのように考えることができます。この仮定は、別表記の文字列のキーがその別表記の文字列に対してその参照を冗長にした可能性があるためです。例:
{ $num ->
[one] an apple
*[other] { $num } apples
}
ここで、この検査の目的のために、[one] 別表記は $num 参照を含むと見なされます。
ただし、Flunt 構文における選択式(Select Expression)のセレクター内での参照は、用語属性の変数でのみ定義できますが、それ自体は必須参照としてカウントされません。 なぜなら、選択式はエンドユーザーが実際に目にする文字列の実際のテキストコンテンツの一部を形成しないからです。 また、選択式の有無はロケール依存とみなされます。例:
{ -term.starts-with-vowel ->
[yes] an { -term }
*[no] a { -term }
}
ここでは、 -term.starts-with-vowel への参照が翻訳に現れることは求められませんが、 -term への参照は現れることが求められます。
Fluent 翻訳内部の HTML¶
Added in version 5.0.
- 概要:
Fluent の対象は有効な内部 HTML である必要があり、整合することが必要です。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.fluent.inner_html.FluentTargetInnerHTMLCheck- 検査の識別子:
fluent-target-inner-html- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-target-inner-html- 除外フラグ:
ignore-fluent-target-inner-html
この検査は、メッセージや用語の翻訳された値が、ソースの値と同じ HTML 要素を含んでいるかどうかを検証します。
まず、ソースの値が Fluent ソース内部の HTML 検査に合格しない場合、この検査は何も行いません。それ以外の場合、翻訳された値も同じ条件の下で検査します。
次に、翻訳された値内で見つかった HTML 要素が、ソースの値内で見つかった HTML 要素と比較されます。2 つの要素は、完全に同じタグ名、同じ属性と値を共有し、すべての祖先も同じ方法で一致する場合に一致します。この検査は、ソース内のすべての要素が翻訳内のどこかに表示され、数 も同じで、追加の要素は追加されていないことを確認します。値内に複数の要素がある場合、それらは翻訳値内で同じ順序で表示される必要はありません。
ソースまたは翻訳に Fluent Select 式が含まれている場合、ソースの各可能な別表記の文字列は、翻訳においても同じ HTML 要素を持つ少なくとも 1 つの別表記の文字列と一致することが必要であり、その逆も同様です。
Fluent を Fluent DOM パッケージと組み合わせて使用する場合、この検査は翻訳にはソースに必須の data-l10n-name 要素や <br> のような許可されたインライン要素が含まれることを確認します。
たとえば、次の原文を考えます。
Source message <img data-l10n-name="icon"/> with icon
下の翻訳は一致します。
Translated message <img data-l10n-name="icon"/> with icon
しかし、下の翻訳は一致しません。
Translated message <img data-l10n-name="new-val"/> with icon
これも一致しません。
Translated message <br data-l10n-name="icon"/> with no icon
Fluent 翻訳構文¶
Added in version 5.0.
- 概要:
翻訳文での Fluent 構文エラー。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.fluent.syntax.FluentTargetSyntaxCheck- 検査の識別子:
fluent-target-syntax- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-target-syntax- 除外フラグ:
ignore-fluent-target-syntax
Weblate では、Fluent 文字列は、参照と別表記に Fluent 構文を使用しますが、属性やセレクタによる別表記、複数形を含む、より複雑な機能も使用できます。この検査は、翻訳で使用される構文が Fluent で有効であることを保証します。
書式指定文字列¶
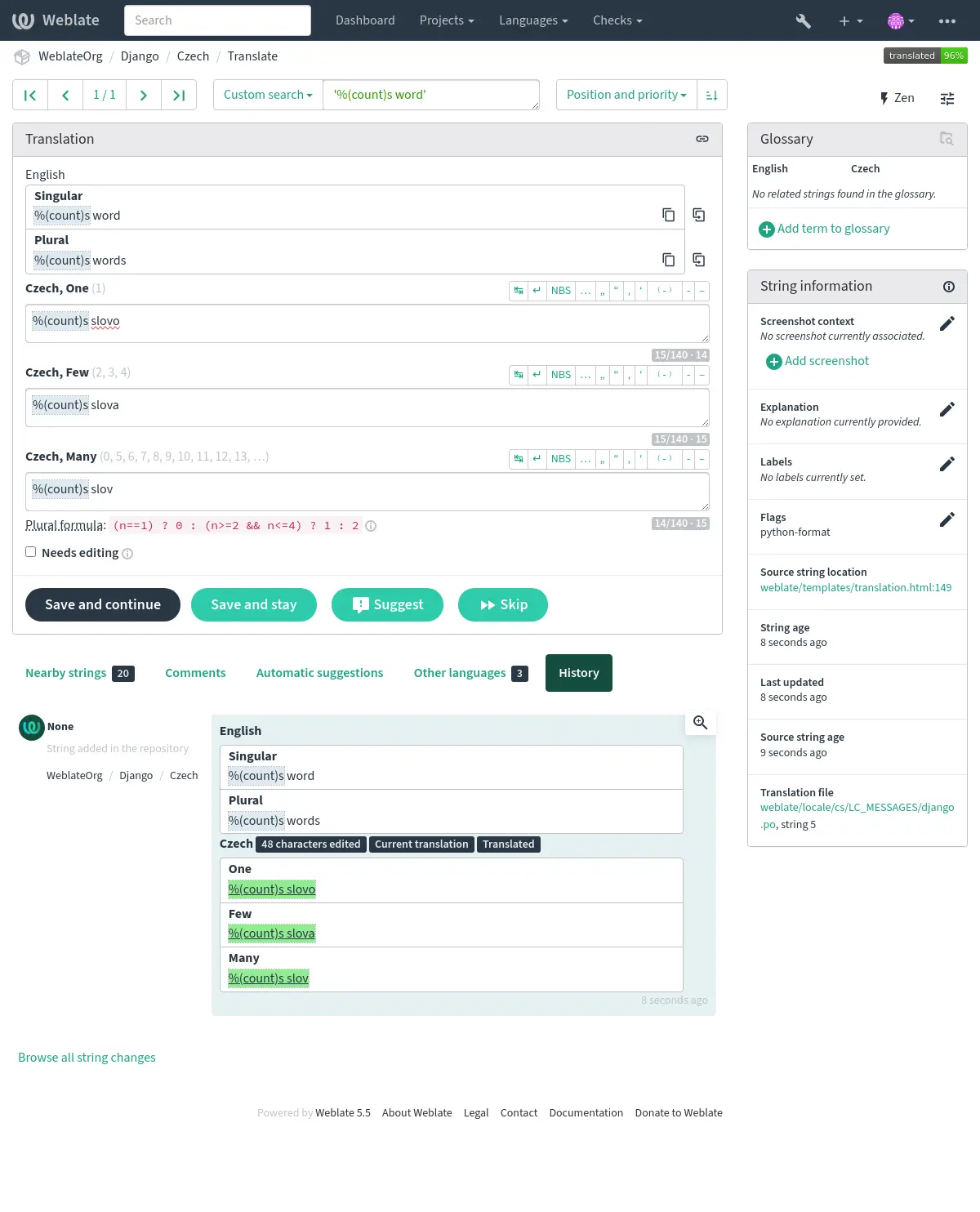
原文から翻訳文に文字列の書式指定が複製されているか検査します。翻訳文で書式指定文字列を省略すると、通常は深刻な問題が発生するので、文字列の書式指定は、通常は原文と一致していなければなりません。
Weblate では、複数の言語での書式指定文字列の検査に対応しています。検査は、文字列に適切なフラグが設定されている場合にのみ自動的に有効になります(例: C 形式の 'c-format')。Gettext はこれを自動的に追加しますが、他のファイル形式や PO ファイルが xgettext で生成されていない場合は、手動で追加することが必要です。
ほとんどのフォーマット検査では、単一の数を持つ複数形に対してフォーマット文字列を省略することが許可されています。これにより、翻訳者はこれらのケースに対してよりわかりやすい文字列(%d apple の代わりに One apple)を書くことができます。無効にするには、strict-format フラグを追加してください。
フラグは、文字列ごとに変更できて(参照: 原文の追加情報)、コンポーネント構成 で行うこともできます。コンポーネントごとに定義する方が簡単ですが、文字列が書式指定文字列として解釈されず、書式指定文字列の構文がすでに使用されている場合は、誤検出が発生することがあります。
ヒント
Weblate で指定した書式指定の検査ができない場合は、汎用の プレースホルダー を使用できます。
検査に加えて、書式指定文字列はハイライトされて翻訳文に簡単に挿入できます:
AngularJS 補間文字列¶
- 概要:
AngularJS 補間文字列が原文と一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.angularjs.AngularJSInterpolationCheck- 検査の識別子:
angularjs_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
angularjs-format- 除外フラグ:
ignore-angularjs-format
- 名前付き書式文字列の例:
Your balance is {{amount}} {{ currency }}
Automattic コンポーネント フォーマット¶
- 概要:
Automattic コンポーネントのプレースホルダーが原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.AutomatticComponentsCheck- 検査の識別子:
automattic_components_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
automattic-components-format- 除外フラグ:
ignore-automattic-components-format
- 単純な書式指定文字列の例:
They bought {{strong}}apples{{/strong}}.
C 言語形式¶
- 概要:
C 言語形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.CFormatCheck- 検査の識別子:
c_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
c-format- 除外フラグ:
ignore-c-format
- 単純な書式指定文字列の例:
There are %d apples- 書式指定文字列の位置の例:
Your balance is %1$d %2$s
C# 形式¶
- 概要:
C# 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.CSharpFormatCheck- 検査の識別子:
c_sharp_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
c-sharp-format、csharp-format- 除外フラグ:
ignore-c-sharp-format
- 書式指定文字列の位置の例:
There are {0} apples
ECMAScript テンプレート リテラル¶
- 概要:
ECMAScript テンプレート リテラルが原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.ESTemplateLiteralsCheck- 検査の識別子:
es_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
es-format- 除外フラグ:
ignore-es-format
- 補間の例:
There are ${number} apples
i18next 補間¶
Added in version 4.0.
- 概要:
i18next の補間が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.I18NextInterpolationCheck- 検査の識別子:
i18next_interpolation- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
i18next-interpolation- 除外フラグ:
ignore-i18next-interpolation
- 補間の例:
There are {{number}} apples- ネスティングの例:
There are $t(number) apples
ICU MessageFormat¶
Added in version 4.9.
- 概要:
ICU MessageFormat 文字列の構文エラーやプレースホルダーの不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.icu.ICUMessageFormatCheck- 検査の識別子:
icu_message_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
icu-message-format- 除外フラグ:
ignore-icu-message-format
- 補間の例:
There {number, plural, one {is one apple} other {are # apples}}.
この検査は、純粋な ICU MessageFormat メッセージと、単純な XML タグを持つ ICU の両方に対応します。XML 対応を選択するか、特定の検査の詳細を無効にすることで、 icu-flags:* を使用してこの検査の動作を設定できます。たとえば、次のフラグは、複数のサブ メッセージの検証を無効にしながら XML 対応を有効にします。
icu-message-format, icu-flags:xml:-plural_selectors
|
単純な XML タグに対応を有効にします。デフォルトでは、XML タグは寛大に解析されます。対でない |
|
厳格な XML タグに対応を有効にします。タグの一部でない場合は、すべての |
|
エディタ内のプレースホルダーの強調表示を無効にします。 |
|
サブメッセージに |
|
サブメッセージ セレクターがソースと一致するかどうかの検査を除外します。 |
|
プレースホルダーの型が原文と一致するかどうかの検査を除外します。 |
|
原文に存在しなかったプレースホルダーが、存在しない確認の検査を除外します。 |
|
原文に存在していたプレースホルダーが、欠落していない確認の検査を除外します。 |
また、 strict-xml が無効で xml が有効な場合は、icu-tag-prefix:PREFIX フラグを使用して、すべての XML タグが特定の文字列で始まることを必須にできます。次のようにフラグを設定して、XML タグが <x: で始まる場合にのみ一致することを許可する例:
icu-message-format, icu-flags:xml, icu-tag-prefix:"x:"
これは <x:link>click here</x:link> と一致しますが、<strong>this</strong> とは一致しません。
Java 形式¶
- 概要:
Java 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.JavaFormatCheck- 検査の識別子:
java_printf_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
Android 文字列リソース、モバイル Kotlin リソース、Compose Multiplatform のリソース
- 有効にするフラグ:
java-printf-format- 除外フラグ:
ignore-java-printf-format
- 単純な書式指定文字列の例:
There are %d apples- 書式指定文字列の位置の例:
Your balance is %1$d %2$s
バージョン 4.14 で変更: 以前は、java-format フラグを使用して切り替えていましたが、GNU gettext との一貫性を保つために変更されました。
Java MessageFormat¶
- 概要:
Java MessageFormat 文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.JavaMessageFormatCheck- 検査の識別子:
java_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
auto-java-messageformat,java-format- Automatic flag behavior:
auto-java-messageformat: Treat a text as conditional Java MessageFormat, enabling Java MessageFormat only when the source contains Java MessageFormat placeholders.- 除外フラグ:
ignore-java-format
- 書式指定文字列の位置の例:
There are {0} apples
バージョン 4.14 で変更: 以前は、java-messageformat フラグを使用して切り替えていましたが、GNU gettext との一貫性を保つために変更されました。
この検査は、書式文字列が Java MessageFormat クラスに対して有効であることを検証します。中括弧内の書式文字列を照合するだけでなく、特別な意味を持つ単一引用符も検証します。シングル クォーテーションを書くときは常に '' と書くべきです。対になっていない場合は、引用の始まりとして扱われ、文字列のレンダリング時に表示されません。
JavaScript 形式¶
- 概要:
JavaScript 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.JavaScriptFormatCheck- 検査の識別子:
javascript_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
javascript-format- 除外フラグ:
ignore-javascript-format
- 単純な書式指定文字列の例:
There are %d apples
Laravel 形式¶
- 概要:
Laravel 形式の文字列がソースと一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.LaravelFormatCheck- 検査の識別子:
laravel_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
laravel-format- 除外フラグ:
ignore-laravel-format
- 名前付き書式文字列の例:
The :attribute must be :value
Lua 形式¶
- 概要:
Lua 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.LuaFormatCheck- 検査の識別子:
lua_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
lua-format- 除外フラグ:
ignore-lua-format
- 単純な書式指定文字列の例:
There are %d apples
Object Pascal 形式¶
- 概要:
Object Pascal 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.ObjectPascalFormatCheck- 検査の識別子:
object_pascal_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
object-pascal-format- 除外フラグ:
ignore-object-pascal-format
- 単純な書式指定文字列の例:
There are %d apples
Objective‑C 形式¶
Added in version 5.17.
- 概要:
Objective‑C の書式文字列が元の文字列と一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.ObjCFormatCheck- 検査の識別子:
objc_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
objc-format- 除外フラグ:
ignore-objc-format
パーセントのプレースホルダー¶
Added in version 4.0.
- 概要:
% プレースホルダーが原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PercentPlaceholdersCheck- 検査の識別子:
percent_placeholders- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
percent-placeholders- 除外フラグ:
ignore-percent-placeholders
- 単純な書式指定文字列の例:
There are %number% apples
参考
Perl ブレース形式¶
- 概要:
Perl ブレース書式の指定文字列が原文と一致しない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PerlBraceFormatCheck- 検査の識別子:
perl_brace_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
perl-brace-format- 除外フラグ:
ignore-perl-brace-format
- 名前付き書式文字列の例:
There are {number} apples
Perl 形式¶
- 概要:
Perl 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PerlFormatCheck- 検査の識別子:
perl_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
perl-format- 除外フラグ:
ignore-perl-format
- 単純な書式指定文字列の例:
There are %d apples- 書式指定文字列の位置の例:
Your balance is %1$d %2$s
PHP 形式¶
- 概要:
PHP 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PHPFormatCheck- 検査の識別子:
php_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
php-format- 除外フラグ:
ignore-php-format
- 単純な書式指定文字列の例:
There are %d apples- 書式指定文字列の位置の例:
Your balance is %1$d %2$s
Python ブレース形式¶
- 概要:
Python ブレース形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PythonBraceFormatCheck- 検査の識別子:
python_brace_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
python-brace-format- 除外フラグ:
ignore-python-brace-format
- 単純な書式指定文字列:
There are {} apples- 名前付き書式文字列の例:
Your balance is {amount} {currency}
Python 形式¶
- 概要:
Python 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.PythonFormatCheck- 検査の識別子:
python_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
python-format- 除外フラグ:
ignore-python-format
- 単純な書式指定文字列:
There are %d apples- 名前付き書式文字列の例:
Your balance is %(amount)d %(currency)s
Qt 形式¶
- 概要:
Qt 書式文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.qt.QtFormatCheck- 検査の識別子:
qt_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
qt-format- 除外フラグ:
ignore-qt-format
- 書式指定文字列の位置の例:
There are %1 apples
Qt 複数形式¶
- 概要:
Qt 複数形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.qt.QtPluralCheck- 検査の識別子:
qt_plural_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
qt-plural-format- 除外フラグ:
ignore-qt-plural-format
- 複数形の書式指定文字列の例:
There are %Ln apple(s)
Ruby 形式¶
- 概要:
Ruby 書式文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.ruby.RubyFormatCheck- 検査の識別子:
ruby_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
ruby-format- 除外フラグ:
ignore-ruby-format
- 単純な書式指定文字列の例:
There are %d apples- 書式指定文字列の位置の例:
Your balance is %1$f %2$s- 名前付き書式文字列の例:
Your balance is %+.2<amount>f %<currency>s- 名前付きテンプレート文字列:
Your balance is %{amount} %{currency}
Scheme 形式¶
- 概要:
Scheme 形式の文字列が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.SchemeFormatCheck- 検査の識別子:
scheme_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
scheme-format- 除外フラグ:
ignore-scheme-format
- 単純な書式指定文字列の例:
There are ~d apples
Vue I18n 形式¶
- 概要:
Vue I18n 形式が原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.format.VueFormattingCheck- 検査の識別子:
vue_format- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
vue-format- 除外フラグ:
ignore-vue-format
- 名前付きフォーマット:
There are {count} apples- Rails i18n 形式:
There are %{count} apples- リンクしたロケール メッセージ:
@:message.dio @:message.the_world!
過去に翻訳済み¶
- 概要:
過去に翻訳済みのもの。
- 対象範囲:
すべての文字列
- 検査クラス:
weblate.checks.consistency.TranslatedCheck- 検査の識別子:
translated- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-translated
文字列が以前に翻訳されていることを意味します。これは、VCS で翻訳が巻き戻された場合や、その他の理由で翻訳が失われた場合に発生します。
一貫性の欠如¶
- 概要:
この文字列は、このプロジェクトで複数の翻訳があるか、コンポーネントによっては翻訳されていないものもあります。
- 対象範囲:
すべての文字列
- 検査クラス:
weblate.checks.consistency.ConsistencyCheck- 検査の識別子:
inconsistent- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-inconsistent
Weblate は、同一の文字列の翻訳が一貫性を維持できるように、プロジェクト内のすべての翻訳を検査します。
1 つの文字列についてプロジェクト内で異なる翻訳がある場合、検査では不合格となります。この場合、検査結果には一貫性の欠如と表示されます。この文字列の他の翻訳は その他の出現箇所 タブで確認できます。
この検査は、翻訳の自動反映の有効化 が有効化されているプロジェクト内のすべてのコンポーネントに適用されます。
ヒント
パフォーマンス上の理由から、検査ですべての不整合が検出されずに一致する数が制限されます。
注釈
この検査は、文字列があるコンポーネントでは翻訳されていて、別のコンポーネントでは未翻訳の場合にも発生します。これは、その他の出現箇所 タブの各行に表示される この翻訳を使う ボタンをクリックするだけで、一部のコンポーネントで翻訳されていない文字列を手動で処理する簡単な方法として使用できます。
自動翻訳 アドオンを使用して、別のコンポーネントですでに翻訳されている、新しく追加された文字列の翻訳を自動化できます。
reStructuredText の不整合¶
Added in version 5.10.
- 概要:
翻訳済みメッセージの reStructuredText マークアップに一貫性がない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.RSTReferencesCheck- 検査の識別子:
rst-references- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
rst-text- 除外フラグ:
ignore-rst-references
reStructuredText の用語参照やその他のマークアップが原文と一致しません。このエラーの典型的な原因:
バッククォート(`)の不一致、または不足。
参照の前後にスペースや句読点が欠けている。reStructuredText のインラインブロックは、単語以外の文字で区切る必要がある。
インラインタグとバッククォート(`)の間にスペースが入っている。
参照名が翻訳されていない。
バッククォート(`)の代わりに引用符を使用している。
置換記法や脚注参照の不一致。
Kashida 文字の使用¶
- 概要:
装飾的なカシーダは使用すべきでない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.KashidaCheck- 検査の識別子:
kashida- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-kashida
Kashida の装飾文字は翻訳に使用しないでください。これは Tatweel とも呼ばれます。
Markdown のリンク¶
- 概要:
Markdown リンクが原文と一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.MarkdownLinkCheck- 検査の識別子:
md-link- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
md-text- 除外フラグ:
ignore-md-link
Markdown リンクが原文と一致しません。
Markdown の参照¶
- 概要:
Markdown リンクの参照が原文と一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.MarkdownRefLinkCheck- 検査の識別子:
md-reflink- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
md-text- 除外フラグ:
ignore-md-reflink
Markdown リンクの参照が原文と一致しません。
Markdown 構文¶
- 概要:
Markdown 構文が原文と一致しません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.MarkdownSyntaxCheck- 検査の識別子:
md-syntax- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
md-text- 除外フラグ:
ignore-md-syntax
Markdown 構文が原文と一致しません
翻訳の最大文字数¶
- 概要:
翻訳文は、設定した文字数を超えてはいけない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.MaxLengthCheck- 検査の識別子:
max-length- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
max-length- 除外フラグ:
ignore-max-length
翻訳文が使用可能なスペースに収まる文字列数かどうかを検査します。これは、翻訳文の文字列数のみの検査です。
他の検査とは違い、フラグは max-length:100 のような key:value ペアとして設定が必要です。
The max-length flag also triggers 原文の文字列の長さ for source
strings. For English source strings, including English variants, this check
warns when the source uses more than 85% of the configured length to leave room
for translation expansion. For other source languages, the configured
max-length is used directly.
ヒント
この検査では文字数を確認するので、プロポーショナル フォントを使用してテキストを表示する場合は適さないかもしれません。翻訳の文字の最大サイズ 検査は、テキストの実際の表示結果を検査します。
replacements: フラグは、文字列を検査する前に置換可能な要素を展開する場合にも便利です。
xml-text フラグも使用している場合、長さの計算では XML タグが無視されます。
翻訳の文字の最大サイズ¶
- 概要:
Rendered text should not exceed given size.
- 対象範囲:
source and translated strings
- 検査クラス:
weblate.checks.render.MaxSizeCheck- 検査の識別子:
max-size- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
max-size- 除外フラグ:
ignore-max-size
Rendered source or translation text should not exceed given size. It renders the text and checks if it fits into given boundaries. Word wrapping is applied when more than one line is configured.
この検査には、最大幅と最大行数の 1 つまたは 2 つのパラメータが必要です。行数を指定しない場合は、1 行のテキストと判断されます。
使用するフォントは font-* ディレクティブ(参照: フラグを使用した動作の設定)でも設定できます。次は、ubuntu のフォントサイズ 22 で表示するテキストを、2 行 500 ピクセルに収める翻訳フラグの設定方法:
max-size:500:2, font-family:ubuntu, font-size:22
ヒント
コンポーネント構成 内の font-* ディレクティブを設定して、コンポーネント内のすべての文字列に同じフォントを設定できます。文字列ごとに設定することが必要な場合に備えて、文字列ごとにこれらの値を上書きできます。
replacements: フラグは、文字列を検査する前に置換可能な要素を展開する場合にも便利です。
xml-text フラグも使用している場合、長さの計算では XML タグが無視されます。
\n の不一致¶
- 概要:
改行文字(\n)の数が原文と一致しないもの。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EscapedNewlineCountingCheck- 検査の識別子:
escaped_newline- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-escaped-newline
通常、エスケープされた改行はプログラムの出力をフォーマットする際に重要です。翻訳の \n リテラルの数が原文と一致しない場合、検査で不合格となります。
コロンの不一致¶
- 概要:
原文と翻訳文で一致しない文末のコロン。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndColonCheck- 検査の識別子:
end_colon- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-colon
原文と翻訳がどちらもコロンで終わっているか検査します。コロンを使わないさまざまな言語(中国語または日本語)についても検査されます。
省略記号の不一致¶
- 概要:
原文と翻訳文で一致しない文末の省略記号。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndEllipsisCheck- 検査の識別子:
end_ellipsis- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-ellipsis
原文から翻訳文に末尾の省略記号が複製されているか検査します。これは、3 つのドット (...) ではなく、実際の省略記号 (…) のみを検査します。
省略記号は通常、3 つのドットよりも綺麗に表示され、音声合成ではより適切に読み上げられます。
感嘆符の不一致¶
- 概要:
原文と翻訳文で一致しない文末の感嘆符。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndExclamationCheck- 検査の識別子:
end_exclamation- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-exclamation
原文から翻訳に感嘆符が複製されているか検査します。感嘆符の有無は、感嘆符を持たないさまざまな言語についても検査されます(中国語、日本語、韓国語、アルメニア語、リンブ語、ミャンマー語、またはンコ語)。
終止符の不一致¶
- 概要:
原文と翻訳文で一致しない文末の終止符。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndStopCheck- 検査の識別子:
end_stop- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-stop
原文から翻訳に終止符が複製されているか検査します。終止符の有無は、ピリオド (.) を使わない複数の言語(中国語、日本語、デーヴァナーガリー文字またはウルドゥー語)でも検査します。
感嘆符疑問符の不一致¶
- 概要:
原文と翻訳文で一致しない文末の感嘆符疑問符。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndInterrobangCheck- 検査の識別子:
end_interrobang- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-interrobang
原文から翻訳に感嘆符疑問符が複製されているか検査します。「!?」と「?!」は同じものとみなします。
疑問符の不一致¶
- 概要:
原文と翻訳文で一致しない文末の疑問符。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndQuestionCheck- 検査の識別子:
end_question- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-question
原文から翻訳文に疑問符が複製されているか検査します。疑問符の有無は、疑問符を持たない複数の言語(アルメニア語、アラビア語、中国語、韓国語、日本語、エチオピア語、ヴァイ語またはコプト語)についても検査します。
セミコロンの不一致¶
- 概要:
原文と翻訳文で一致しない文末のセミコロン。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndSemicolonCheck- 検査の識別子:
end_semicolon- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-semicolon
原文から翻訳文に、末尾のセミコロンが複製されているか検査します。
改行数の不一致¶
- 概要:
改行の数が原文と一致しない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.NewLineCountCheck- 検査の識別子:
newline-count- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-newline-count
通常、改行はプログラムの出力をフォーマットするために重要です。翻訳の改行数が原文と一致しない場合、検査で不合格となります。
複数形の不足¶
- 概要:
翻訳されなかった複数形がある。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.consistency.PluralsCheck- 検査の識別子:
plurals- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-plurals
原文のすべての複数形が翻訳されているか検査します。各複数形の使用方法の詳細については、文字列の定義で確認できます。
複数形を記入しないと、複数形が使用されているときに何も表示されないことがあります。
複数の大文字¶
Added in version 5.16.
- 概要:
翻訳文に誤って複数の大文字を含む単語がある。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.MultipleCapitalCheck- 検査の識別子:
multiple_capital- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-multiple-capital
誤った大文字化を検出するために、通常は小文字または一般的な大文字化で書かれる文中で、連続した大文字を含む単語(例: HEllo や CAmelCase)を検査します。元の文字列に大文字が含まれている場合、翻訳でも同様に大文字を使用して構いません。
カビーレ語の非標準文字¶
Added in version 5.12.
- 概要:
標準化されたラテン・カビル文字を使用してください(例: ギリシャ文字の γ の代わりに ɣ、ε の代わりに ɛ)。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.KabyleCharactersCheck- 検査の識別子:
kabyle-characters- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-kabyle-characters
カビル語の翻訳で、カビル語の文字が Unicode で標準化される前によく使用されていた類似のギリシャ語の文字ではなく、正しいカビル語の文字が使用されていることを検査します。
プレースホルダー¶
バージョン 4.3 で変更: 正規表現をプレースホルダーとして使用できる。
バージョン 4.13 で変更: case-insensitive フラグを使用すると、プレースホルダーは大文字と小文字を区別しなくなります。
- 概要:
翻訳文にプレースホルダーが不足している。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.placeholders.PlaceholderCheck- 検査の識別子:
placeholders- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
placeholders- 除外フラグ:
ignore-placeholders
一部のプレースホルダーが翻訳に欠けています。これらは翻訳ファイルから抽出されるか、placeholders フラグを使用して手動で定義します。フラグはコロンで区切り、スペースを含む文字列は引用符で囲んで使用します。
placeholders:$URL$:$TARGET$:"some long text"
プレースホルダーに構文がある場合の、正規表現の使用例:
placeholders:r"%[^% ]%"
大文字と小文字を区別しないプレースホルダーも可能:
placeholders:$URL$:$TARGET$,case-insensitive
禁止されている頭文字¶
Added in version 5.9.
- 概要:
文字列が CSV の禁止文字で始まっています。
- 対象範囲:
用語集の文字列
- 検査クラス:
weblate.checks.glossary.ProhibitedInitialCharacterCheck- 検査の識別子:
prohibited_initial_character- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-prohibited-initial-character
用語集は CSV 形式で共有されることが多く、先頭に特定の文字を使用すると、テキストが式として評価されてしまうため、多くのアプリケーションで制限されています。これは 自動提案における用語集 にも影響し、用語集の同期に CSV を使用する多くのサービスが、そのような文字列を拒否します。
句読点のスペース¶
バージョン 5.10 で変更: この検査は以前はブルトン語にも適用されていましたが、現在はフランス語のみに限定されています。
- 概要:
二重句読点の前に改行しないスペースがない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.PunctuationSpacingCheck- 検査の識別子:
punctuation_spacing- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-punctuation-spacing
二重句読点(感嘆符、疑問符、セミコロン、コロン)の前に、改行不可のスペースが入っているかを検査します。この規則は、二重句読点の前にスペースを入れることが組版上の規則となっているフランス語など、限られた言語でのみ使用されます。
正規表現¶
バージョン 5.10 で変更: Unicode のコードポイント特性を含む、高度な正規表現などの追加機能に対応。
- 概要:
翻訳文が正規表現に一致しない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.placeholders.RegexCheck- 検査の識別子:
regex- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
regex- 除外フラグ:
ignore-regex
翻訳文には正規表現に一致するものはありません。正規表現は、翻訳ファイルから抽出するか、regex フラグを使用して手動で定義します。例:
regex:^foo|bar$
一致では、スクリプトやブロックを含む Unicode のコードポイント特性にも対応しています。
regex:^[-_\p{L}\p{N}\p{sc=Deva}\p{sc=Thai}]{1,32}$
ヒント
プレースホルダーの欠落を検出するには、プレースホルダー を使用してください。
参考
reStructuredText 構文エラー¶
Added in version 5.10.
- 概要:
翻訳に reStructuredText の構文エラーがあります。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.RSTSyntaxCheck- 検査の識別子:
rst-syntax- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
rst-text- 除外フラグ:
ignore-rst-syntax
翻訳内の reStructuredText 構文エラー。確認すべき問題点:
タグの開始と終了が対応していない。
参照の前後にスペースや句読点が欠けている。reStructuredText のインラインブロックは、単語以外の文字で区切る必要がある。
バッククォート(`)の代わりに引用符を使用している。
他で使用された翻訳¶
Added in version 4.18.
- 概要:
異なる文字列が同じように翻訳されています。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.consistency.ReusedCheck- 検査の識別子:
reused- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-reused
同じ翻訳が異なる原文で使用されている場合、検査は失敗します。このような翻訳は意図的なものである可能性もありますが、ユーザーを混乱させる可能性もあります。
Safe MDX¶
Added in version 2026.7.
- 概要:
JSX expressions in the translation do not match the source.
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.mdx.SafeMDXCheck- 検査の識別子:
safe-mdx- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
safe-mdx- 除外フラグ:
ignore-safe-mdx
同一の複数形¶
- 概要:
同じように翻訳されている複数形がある。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.consistency.SamePluralsCheck- 検査の識別子:
same-plurals- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-same-plurals
翻訳文の複数形のうち、一致しているものがあるかを検出します。ほとんどの言語では、複数形はそれぞれ異なっている必要があります。
文頭の改行¶
- 概要:
原文と翻訳文で一致しない文頭の改行。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.BeginNewlineCheck- 検査の識別子:
begin_newline- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-begin-newline
改行は通常、適切な理由で原文に含まれています。省略や追加をすると、翻訳されたテキストを使ったときにフォーマットが崩れることがあります。
参考
先頭の空白¶
- 概要:
原文と翻訳文で一致しない文頭のスペース数。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.BeginSpaceCheck- 検査の識別子:
begin_space- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-begin-space
文字列の先頭にあるスペースは、通常、インターフェイスのインデントに使用されるため、維持することが重要です。
文末の改行¶
- 概要:
原文と翻訳文で一致しない末尾の改行。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndNewlineCheck- 検査の識別子:
end_newline- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-newline
改行は通常、適切な理由で原文に含まれています。省略や追加をすると、翻訳されたテキストを使ったときにフォーマットが崩れることがあります。
参考
文末の空白¶
- 概要:
原文と翻訳文で一致しない末尾のスペース。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.EndSpaceCheck- 検査の識別子:
end_space- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-end-space
原文から翻訳に末尾のスペースが複製されているか検査します。
通常、末尾のスペースは隣接する要素の間を空けるためにあるので、削除するとレイアウトが壊れることがあります。
未翻訳の翻訳文¶
- 概要:
原文と翻訳文が同一。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.same.SameCheck- 検査の識別子:
same- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-same
原文と対応する翻訳文字列が、複数形のうち少なくとも 1 つまで同一である場合に発生します。すべての言語に共通する一部の文字列は無視され、さまざまなマークアップは除去されます。これにより、誤検出の数が減ります。
この検査は、誤って翻訳されていない文字列を見つけるのに便利です。
この検査のデフォルトの動作では、初期設定の用語リストにある単語を検査対象から除外されます。これらは翻訳されないことが多い単語です。これは、複数の言語で同じ 1 つの単語だけで構成される短い文字列での誤検出を避けるために有効です。このリストを無効にするには、文字列またはコンポーネントに strict-same フラグを追加します。
バージョン 4.17 で変更: check-glossary フラグ(参照: 用語集に従っていない)フラグを使用すると、用語集の翻訳禁止用語は検査から除外されます。
安全でない HTML¶
- 概要:
翻訳文には、安全でない HTML マークアップが使用されている。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.SafeHTMLCheck- 検査の識別子:
safe-html- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
auto-safe-html,safe-html- Automatic flag behavior:
auto-safe-html: Treat a text as conditional HTML, enabling 安全でない HTML only for plain text or source strings that contain standard HTML markup or valid custom elements. This is useful for extended Markdown variants such as MDX, where angle-bracket syntax may not be HTML.- 除外フラグ:
ignore-safe-html
翻訳には、安全でない HTML マークアップが含まれています。この検査は safe-html フラグ(参照: フラグを使用した動作の設定)を使用して有効にしなければなりません。マークアップを自動的にサニタイズできる autofixer も付属しています。
ヒント
また、md-text フラグを使用している場合には、Markdown 形式のリンクも許可されます。
参考
HTML の検査は Ammonia ライブラリで処理されます。
URL¶
- 概要:
翻訳には URL が含まれていません。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.URLCheck- 検査の識別子:
url- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- 有効にするフラグ:
url- 除外フラグ:
ignore-url
The translation does not contain a URL. This is triggered only in case the unit is marked as containing URL. In that case the translation has to be a valid URL.
XML マークアップ¶
- 概要:
翻訳文の XML タグが原文と不一致。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.XMLTagsCheck- 検査の識別子:
xml-tags- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-xml-tags
これは通常、出力結果が異なることを意味します。ほとんどの場合、これは翻訳の変更による望ましい結果ではありませんが、場合によっては変更されることもあります。
原文から翻訳文に XML タグが複製されているか検査します。
この検査は、XML のような文字列に対しては自動的に有効になります。強制的に有効にするため、場合によっては xml-text フラグの追加が必要になります。
注釈
この検査は safe-html フラグにより無効にされています。このフラグによって行われる HTML のクリーンアップにより、無効な XML の HTMLマークアップを生成する可能性があるためです。
XML 構文¶
- 概要:
翻訳文が XML として正しくない。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.markup.XMLValidityCheck- 検査の識別子:
xml-invalid- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-xml-invalid
XML マークアップは無効です。
この検査は、XML のような文字列に対しては自動的に有効になります。強制的に有効にするため、場合によっては xml-text フラグの追加が必要になります。
注釈
この検査は safe-html フラグにより無効にされています。このフラグによって行われる HTML のクリーンアップにより、無効な XML の HTMLマークアップを生成する可能性があるためです。
ゼロ幅スペース¶
- 概要:
ゼロ幅スペース文字を含む翻訳文。
- 対象範囲:
翻訳済みの文字列
- 検査クラス:
weblate.checks.chars.ZeroWidthSpaceCheck- 検査の識別子:
zero-width-space- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-zero-width-space
単語の途中でのメッセージの改行(ワードラッピング)に、ゼロ幅スペース(<U+200B>)が使われています。
通常は誤って挿入するため、この検査は翻訳中に検出した時点で起動します。この文字を使用すると、一部のプログラムで問題が発生することがあります。
原文検査¶
原文検査は、開発者が原文の品質を向上させるため便利です。
省略記号¶
- 概要:
この文字列は、省略記号
(…)ではなく 3 つのドット(...)を使用しています。- 対象範囲:
原文
- 検査クラス:
weblate.checks.source.EllipsisCheck- 検査の識別子:
ellipsis- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-ellipsis
これは、文字列で省略記号 (…) を使用すべきところで、3 つのドット (...) を使用すると不合格となります。
ほとんどの場合、Unicode 文字を使用する方が適切な方法であり、表示の品質も高くなります。また、テキスト読み上げでもより適切な音声になります。
Fluent ソース内部の HTML¶
Added in version 5.0.
- 概要:
Fluent ソースは有効な内部 HTML であることが必要です。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.fluent.inner_html.FluentSourceInnerHTMLCheck- 検査の識別子:
fluent-source-inner-html- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-source-inner-html- 除外フラグ:
ignore-fluent-source-inner-html
Fluentは、しばしばメッセージ(または用語)の値が、一部の HTML 要素の .textContent ではなく .innerHTML として直接使用される文脈で使用されます。たとえば、Fluent DOM パッケージを使用する場合などです。
The aim of this check is to predict how the value will be parsed as inner HTML, assuming an HTML5 conforming parser, to catch cases where there would be some "unintended" loss of the string, without being too strict about technical parsing errors that do not lead to a loss of the string.
この検査は、Fluent メッセージや用語の値に適用されますが、その属性には適用されません。メッセージの場合、Fluent 属性は通常 HTML 属性値であり、任意の文字列を含むことができます。用語の場合、Fluent 属性は通常、Fluent 選択式のセレクタ内でのみ参照できる言語プロパティです。
Generally, most Fluent values are not expected to contain any HTML markup. Therefore, this check does not expect or want translators and developers to have to care about strictly avoiding any technical HTML5 parsing errors (let alone XHTML parsing errors). Instead, this check will just want to warn them when they may have unintentionally opened an HTML tag or inserted a character reference.
さらに、HTML タグや文字参照を意図的に含む Fluent の値については、この検査により、タグが閉じているか終了タグと一致するか、有効な文字参照、引用符で囲まれた属性値といった「望ましい書き方」が守られているかを検証します。加えて、HTML5 仕様では技術的にはかなり自由なタグ名や属性名が許容されていますが、この検査では標準的な HTML5 要素や属性を網羅できる基本的な ASCII の値に制限しつつ、一部 のカスタム要素名や属性名も許可します。これは、ユーザーが意図的に HTML を使用していることを部分的に保証するためです。
例:
値 |
警告? |
理由 |
|---|---|---|
|
yes |
|
|
no |
|
|
yes |
終了タグがありません。 |
|
yes |
|
|
no |
カスタム要素タグと対応する閉じタグ。 |
|
no |
|
|
no |
|
|
yes |
属性値が引用符で囲まれていません。 |
|
yes |
非 ASCII タグ名。 |
|
yes |
|
|
no |
文字参照は意図的なようです。 |
|
yes |
|
|
yes |
文字参照は無効です。 |
|
yes |
Fluent の変数が意図せずタグになる可能性があります。 |
|
yes |
Fluent の変数が意図せずに文字参照になる可能性があります。 |
注釈
この検査は、inner HTML の安全性やサニタイズされていることを 保証しません。さらに、inner HTML を意図的に変更しようとする悪意のある試みに対して保護するものではありません。さらに、Fluent の変数や参照は任意の文字列に展開されることがあるため、エスケープされていない限り任意の HTML に展開されることがあります。ただし、例外的に、Fluent の参照の前に < または & 文字がある場合、これによりこの検査が起動します。なぜなら、エスケープされた値でも予期しない結果につながることがあるためです。
注釈
Fluent DOM パッケージには、この検査が強制しないような、許可されるタグや属性などの制限があります。
Fluent ソース構文¶
Added in version 5.0.
- 概要:
原文での Fluent 構文エラー。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.fluent.syntax.FluentSourceSyntaxCheck- 検査の識別子:
fluent-source-syntax- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
fluent-source-syntax- 除外フラグ:
ignore-fluent-source-syntax
Weblate では、Fluent 文字列は参照や変数だけでなく、属性の定義やセレクタによる別表記、複数形を含むようなより複雑な機能にも Fluent の構文が使用されます。この検査は、ソースで使用される構文が Fluent に対して有効であることを保証します。
ICU MessageFormat 構文¶
Added in version 4.9.
- 概要:
ICU MessageFormat 文字列に構文エラーがあります。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.icu.ICUSourceCheck- 検査の識別子:
icu_message_format_syntax- 起動条件:
この検査は、フラグを使用しないと有効化できません。
- この検査を自動的に有効化するファイル形式:
- 有効にするフラグ:
icu-message-format- 除外フラグ:
ignore-icu-message-format
長期間未翻訳¶
Added in version 4.1.
- 概要:
翻訳が放置された文字列。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.source.LongUntranslatedCheck- 検査の識別子:
long_untranslated- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-long-untranslated
文字列が長期間未翻訳のまま放置されていた場合は、原文に問題があり、翻訳が困難である場合があります。
複数言語での検査不合格¶
- 概要:
翻訳は複数の言語で、検査に不合格となった項目があります。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.source.MultipleFailingCheck- 検査の識別子:
multiple_failures- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-multiple-failures
この文字列の翻訳の多くは、品質検査で不合格となっています。これは通常、原文を改善する方法が何かあるという意味です。
この検査の不合格は、文字列の末尾の終止符の欠落など、原文で修正すべきだが翻訳者が翻訳で修正する傾向があるささいな問題によって引き起こされることが多いです。
複数の無名変数¶
Added in version 4.1.
- 概要:
文字列内に名前のない変数が複数あるため、翻訳者が変数を並べ替えることはできません。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.format.MultipleUnnamedFormatsCheck- 検査の識別子:
unnamed_format- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-unnamed-format
文字列内に名前のない変数が複数あるため、翻訳者が変数を並べ替えることはできません。
代わりに、名前付き変数を使用して、翻訳者が変数の順序を変更できるように検討してください。
原文の文字列の長さ¶
- 概要:
Source string is too long to fit into the configured maximum length.
- 対象範囲:
原文
- 検査クラス:
weblate.checks.source.SourceMaxLengthCheck- 検査の識別子:
source-max-length- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-source-max-length
Translations often need more room than the source text, especially when the
source language is English. This check helps maintainers find source strings
that are already close to their configured max-length before translators
have to shorten or omit meaning to fit the limit.
For English source strings, including English variants, the check reports
strings using more than 85% of the configured max-length. For other source
languages, it reports source strings longer than the configured
max-length.
This catches source strings that are likely to make translations fail 翻訳の最大文字数, and source strings that already do not fit the declared limit.
複数形の書式になっていない¶
- 概要:
文字列は複数形として使用されていますが、複数形の書式ではありません。
- 対象範囲:
原文
- 検査クラス:
weblate.checks.source.OptionalPluralCheck- 検査の識別子:
optional_plural- 起動条件:
この検査は常に有効ですが、フラグを使用して検査を除外できます。
- 除外フラグ:
ignore-optional-plural
文字列は複数形として使用されますが、複数形の書式が使われていません。翻訳システムが複数形に対応している場合は、それを使用してください。
Python の Gettext 使用例:
from gettext import ngettext
print(ngettext("Selected %d file", "Selected %d files", files) % files)
自動提案におけるプレースホルダー¶
プレースホルダーに関する検査では、現在のプレースホルダー情報が公開され、これを利用して自動提案エンジンにプレースホルダーを保持するよう指示できます。ただし、このサポート状況はサービスによって異なり、多くの場合、プレースホルダーを確実に保持させる手段はありません。
参考