Überprüfungen und Korrekturen¶
The quality checks help catch common translator errors, ensuring the translation is in good shape. The checks can be ignored in case of false positives. For practical translation guidance around placeholders, markup, punctuation, and plural forms, see Spezielle Texte sicher übersetzen.
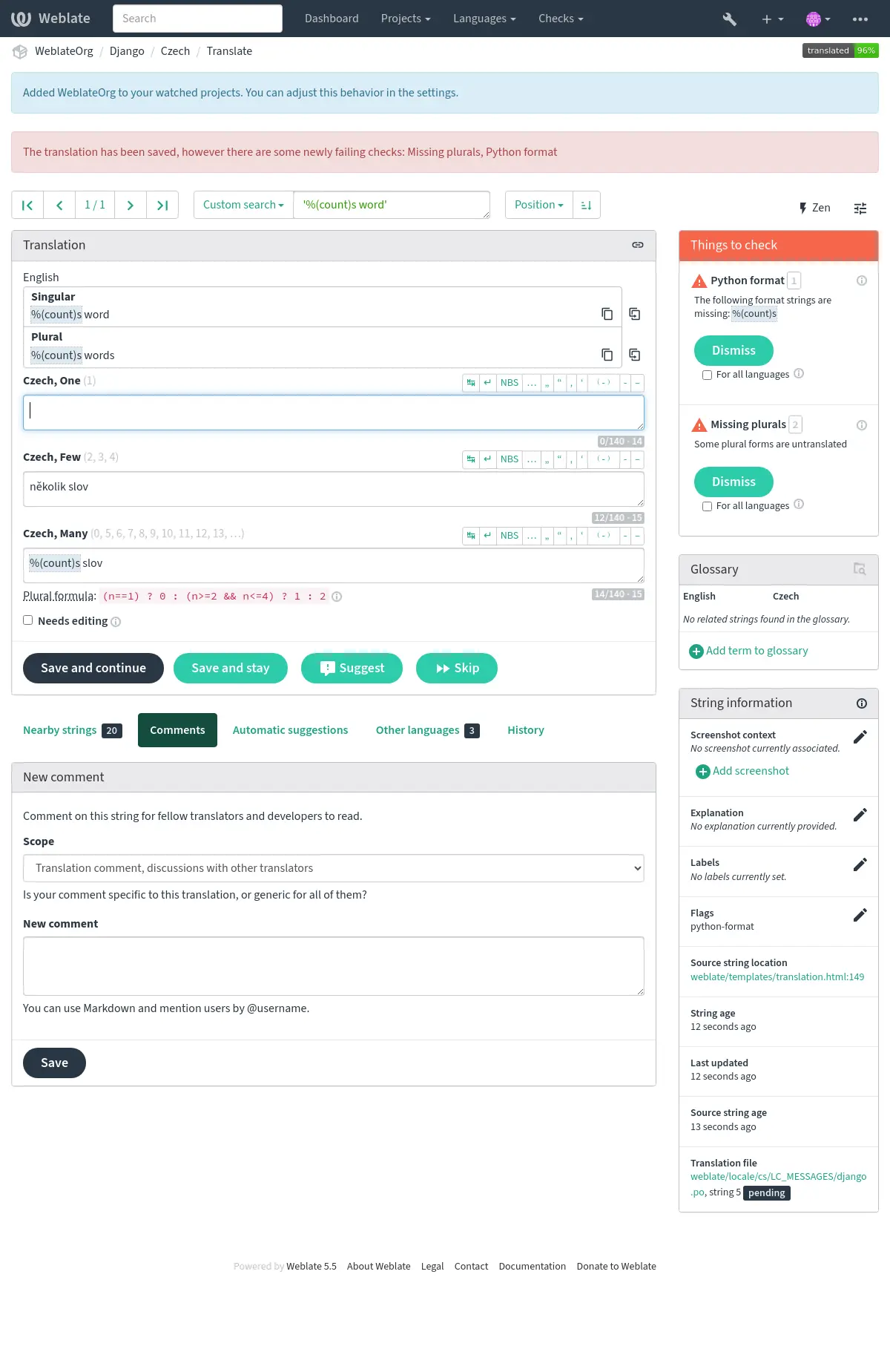
Wenn bei einer eingereichten Übersetzung die Prüfung fehlschlägt, wird dies dem Benutzer sofort angezeigt:
Automatische Korrekturen¶
Ergänzend zu Qualitätsprüfungen, kann Weblate einige häufige Fehler in übersetzten Zeichenketten automatisch beheben. Um keine Fehler hinzuzufügen, sollte diese Funktion mit Bedacht angewendet werden.
Siehe auch
Auslassungspunkte ersetzen¶
- Klassenname:
weblate.trans.autofixes.chars.ReplaceTrailingDotsWithEllipsis
Ersetzt aufeinanderfolgende Punkte (...) durch einen Dreipunkt (…), um eine Übereinstimmung mit der Ausgangszeichenkette herzustellen.
Breitenlose Leerzeichen entfernen¶
- Klassenname:
weblate.trans.autofixes.chars.RemoveZeroSpace
Breitenlose Leerzeichen sind in der Regel in der Übersetzung nicht erwünscht. Mit dieser Korrektur wird es entfernt, sofern es nicht auch in der Ausgangszeichenkette vorhanden ist.
Steuerzeichen entfernen¶
- Klassenname:
weblate.trans.autofixes.chars.RemoveControlChars
Entfernt Steuerzeichen, wenn die Ausgangszeichenkette keine enthält.
Devanagari Danda¶
- Klassenname:
weblate.trans.autofixes.chars.DevanagariDanda
Ersetzt den Satzpunkt in Bangla durch das Devanagari-Danda-Zeichen (।).
Interpunktionszeichenabstand¶
- Klassenname:
weblate.trans.autofixes.chars.PunctuationSpacing
Added in version 5.3.
Stellt sicher, dass Französisch korrekte Interpunktionszeichenabstände verwendet.
Diese Korrektur kann über die Markierung ignore-punctuation-spacing deaktiviert werden (wodurch auch Interpunktionszeichenabstand deaktiviert wird).
Unsicheres HTML bereinigen¶
- Klassenname:
weblate.trans.autofixes.html.BleachHTML
Entfernt unsichere HTML-Auszeichnungen aus Zeichenketten, die als safe-html markiert sind.
Siehe auch
Leerzeichen an Beginn und Ende korrigieren¶
- Klassenname:
weblate.trans.autofixes.whitespace.SameBookendingWhitespace
Stellt führende und nachgestellte Leerzeichen in Übereinstimmung mit der Ausgangszeichenkette her. Das Verhalten kann mit den Markierungen ignore-begin-space und ignore-end-space genau abgestimmt werden, um Teile der Zeichenkette bei der Bearbeitung zu überspringen.
Qualitätsprüfungen¶
Weblate wendet eine Vielzahl von Qualitätsprüfungen für Zeichenketten an. Der folgende Abschnitt beschreibt sie alle im Detail. Es gibt auch sprachspezifische Prüfungen. Bitte melden Sie einen Fehler, wenn etwas falsch gemeldet wird.
Siehe auch
Übersetzungsprüfungen¶
Wird bei jeder Übersetzungsänderung ausgeführt und hilft den Übersetzern, die Qualität der Übersetzungen aufrechtzuerhalten.
Schnelltaste¶
Added in version 2026.7.
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enthalten inkonsistente Schnelltasten.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.AcceleratorKeyCheck- Prüfungskennung:
accelerator- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
accelerator- Markierung zum Ignorieren:
ignore-accelerator
Accelerator keys (also known as mnemonics) let users trigger a UI action from
the keyboard. They are marked in the string by a single punctuation character,
typically & (Qt, Windows), _ (GTK), or ~. Literal marker characters
can usually be escaped by doubling them, and are ignored by this check. Enable
this check with the accelerator: flag to explicitly choose the marker, for
example accelerator:&, accelerator:_, or accelerator:~.
This check verifies that the source and the translation contain the same number of accelerator keys, and that the translation does not contain more than one.
Bemerkung
A string such as Walter & Sons might be translated without the
ampersand and trigger a false positive. Use the ignore-accelerator
flag to skip the check for such strings.
BBCode-Auszeichnung¶
Geändert in Version 5.10: Diese Prüfung stützt sich nicht mehr auf eine unzuverlässige automatische Erkennung, sondern muss jetzt mit der Markierung bbcode-text aktiviert werden.
- Zusammenfassung:
BBCode in der Übersetzung passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.BBCodeCheck- Prüfungskennung:
bbcode- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
bbcode-text- Markierung zum Ignorieren:
ignore-bbcode
BBCode steht für einfache Auszeichnungen, wie z. B. das Hervorheben wichtiger Teile einer Nachricht in Fett- oder Kursivschrift.
Diese Prüfung stellt sicher, dass sie auch in der Übersetzung gefunden werden.
Bemerkung
Die Methode um BBCode zu erkennen ist derzeit noch recht schlicht, so dass diese Prüfung möglicherweise zu Fehlalarmen führt.
Aufeinanderfolgende doppelte Wörter¶
Added in version 4.1.
- Zusammenfassung:
Der Text enthält zweimal hintereinander das gleiche Wort.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.duplicate.DuplicateCheck- Prüfungskennung:
duplicate- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-duplicate
Prüft, ob in einer Übersetzung aufeinanderfolgende doppelte Wörter vorkommen. Dies weist normalerweise auf einen Fehler in der Übersetzung hin.
Hinweis
Diese Prüfung umfasst sprachspezifische Regeln, um Fehlalarme zu vermeiden. Sollte sie fälschlicherweise ausgelöst werden, lassen Sie es uns wissen. Siehe Probleme in Weblate melden.
Folgt nicht dem Glossar¶
Added in version 4.5.
- Zusammenfassung:
Die Übersetzung folgt nicht den definierten Begriffen im Glossar.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.glossary.GlossaryCheck- Prüfungskennung:
check_glossary- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
check-glossary- Markierung zum Ignorieren:
ignore-check-glossary
Diese Prüfung muss mit der Markierung check-glossary aktiviert werden (siehe Verhalten mit Markierungen anpassen). Vor dem Aktivieren bitte Folgendes beachten:
Es wird ein genauer Abgleich der Zeichenkette durchgeführt, wobei das Glossar Begriffe in allen Varianten enthalten sollte.
Das Überprüfen jeder einzelnen Zeichenkette anhand des Glossars ist aufwendig und verlangsamt alle Vorgänge in Weblate, die Überprüfungen wie das Importieren von Zeichenketten oder das Übersetzen beinhalten.
Es werden auch die unübersetzbaren Glossarbegriffe aus Unveränderte Übersetzung benutzt.
Doppeltes Leerzeichen¶
- Zusammenfassung:
Übersetzung enthält doppelte Leerzeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.DoubleSpaceCheck- Prüfungskennung:
double_space- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-double-space
Prüft, ob ein doppeltes Leerzeichen in der Übersetzung vorhanden ist, um Fehlalarme bei anderen Leerzeichen-bezogenen Prüfungen zu vermeiden.
Die Prüfung ist falsch, wenn in der Ausgangszeichenkette ein doppeltes Leerzeichen gefunden wird, da dies bedeutet, dass das doppelte Leerzeichen beabsichtigt ist.
Fluent-Teile¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Teile sollten übereinstimmen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.fluent.parts.FluentPartsCheck- Prüfungskennung:
fluent-parts- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-parts- Markierung zum Ignorieren:
ignore-fluent-parts
Jede Fluent-Nachricht kann einen optionalen Wert (den Haupttextinhalt) und optionale Attribute haben, von denen jedes ein „Teil“ der Meldung ist. In Weblate erscheinen alle diese Teile innerhalb desselben Blocks, wobei eine Fluent-ähnliche Syntax zur Angabe der Attribute verwendet wird. Zum Beispiel:
This is the Message value
.title = This is the title attribute
.alt = This is the alt attribute
Diese Prüfung stellt sicher, dass die übersetzte Nachricht auch einen Wert hat, wenn die Quellnachricht einen hat, oder keinen Wert, wenn die Quelle keinen hat. Außerdem wird geprüft, ob die gleichen Attribute, die in der Quellnachricht verwendet werden, auch in der Übersetzung vorkommen, ohne dass etwas hinzugefügt wird.
Bemerkung
Diese Prüfung wird nicht auf Fluent-Begriffe angewendet, da Begriffe immer einen Wert haben und ihre Attribute in der Regel gebietsschemaspezifisch sind (für Grammatikregeln usw.) und nicht in allen Übersetzungen vorkommen sollen.
Siehe auch
Fluent-Referenzen¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Referenzen sollten übereinstimmen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.fluent.references.FluentReferencesCheck- Prüfungskennung:
fluent-references- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-references- Markierung zum Ignorieren:
ignore-fluent-references
Eine Fluent-Nachricht oder ein Fluent-Begriff kann auf eine andere Nachricht, einen Begriff, ein Attribut oder eine Variable verweisen. Zum Beispiel:
Here is a { message }, a { message.attribute } a { -term } and a { $variable }.
Within a function { NUMBER($num, minimumFractionDigits: 2) }
Im Allgemeinen wird erwartet, dass übersetzte Nachrichten oder Begriffe die gleichen Referenzen enthalten wie die Quelle, wenn auch nicht unbedingt in der gleichen Reihenfolge. Diese Prüfung stellt also sicher, dass die Übersetzungen dieselben Referenzen in ihrem Wert verwenden wie der Quellwert, und zwar in derselben Anzahl und ohne Zusätze. Bei Nachrichten wird auch geprüft, ob jedes Attribut in der Übersetzung die gleichen Referenzen wie das entsprechende Attribut in der Quelle verwendet.
Wenn die Quelle oder Übersetzung Fluent-Select-Ausdrücke enthält, dann muss jede mögliche Variante in der Quelle mit mindestens einer Variante in der Übersetzung mit den gleichen Referenzen übereinstimmen und umgekehrt.
Wenn eine Variablenreferenz sowohl im Selektor des Select-Ausdrucks als auch in einer seiner Varianten erscheint, können alle Varianten so betrachtet werden, als ob sie diese Referenz ebenfalls enthalten. Die Annahme ist, dass der Schlüssel der Variante die Referenz für diese Variante überflüssig gemacht hat. Zum Beispiel:
{ $num ->
[one] an apple
*[other] { $num } apples
}
Für die Zwecke dieser Prüfung wird davon ausgegangen, dass die Variante [one] auch die Referenz $num enthält.
Eine Referenz innerhalb des Selektors des Select-Ausdrucks, die in der Fluent-Syntax nur eine Variable eines Begriff-Attributs sein kann, zählt jedoch nicht als erforderliche Referenz, da sie nicht den tatsächlichen Textinhalt der Zeichenkette abbildet, den der Endbenutzer sehen wird, und das Vorhandensein eines Select-Ausdrucks als gebietsschemaspezifisch betrachtet wird. Zum Beispiel:
{ -term.starts-with-vowel ->
[yes] an { -term }
*[no] a { -term }
}
Hier wird nicht erwartet, dass ein Verweis auf -term.starts-with-vowel in Übersetzungen erscheint, ein Verweis auf -term hingegen schon.
Inneres HTML der Fluent-Übersetzung¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Ziel sollte gültiges inneres HTML sein, welches übereinstimmt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.fluent.inner_html.FluentTargetInnerHTMLCheck- Prüfungskennung:
fluent-target-inner-html- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-target-inner-html- Markierung zum Ignorieren:
ignore-fluent-target-inner-html
Mit dieser Prüfung wird sichergestellt, dass der übersetzte Wert einer Nachricht oder eines Begriffs die gleichen HTML-Elemente enthält wie der Quellwert.
Erstens, wenn der Quellwert die Prüfung Inneres HTML der Fluent-Quelle nicht besteht, dann wird diese Prüfung nichts bewirken. Andernfalls wird auch der übersetzte Wert unter den gleichen Bedingungen geprüft.
Zweitens werden die im übersetzten Wert gefundenen HTML-Elemente mit denen im Quellwert gefundenen verglichen. Zwei Elemente gelten als übereinstimmend, wenn sie genau denselben Tag-Namen, dieselben Attribute und Werte haben und alle ihre Vorgänger auf dieselbe Weise übereinstimmen. Durch diese Prüfung wird sichergestellt, dass alle Elemente in der Quelle irgendwo in der Übersetzung vorkommen, mit der gleichen Anzahl an Vorkommen und ohne zusätzliche Elemente. Wenn der Wert mehrere Elemente enthält, müssen diese nicht in der gleichen Reihenfolge im Übersetzungswert erscheinen.
Wenn die Quelle oder Übersetzung Fluent-Select-Ausdrücke enthält, dann muss jede mögliche Variante in der Quelle mit mindestens einer Variante in der Übersetzung mit den gleichen HTML-Elementen übereinstimmen und umgekehrt.
Wenn Fluent in Kombination mit dem Fluent-DOM-Paket verwendet wird, stellt diese Prüfung sicher, dass die Übersetzung auch alle erforderlichen data-l10n-name-Elemente enthält, die in der Quelle erscheinen, oder alle erlaubten Inline-Elemente wie <br>.
Zum Beispiel die folgende Quelle:
Source message <img data-l10n-name="icon"/> with icon
würde übereinstimmen mit:
Translated message <img data-l10n-name="icon"/> with icon
aber nicht mit:
Translated message <img data-l10n-name="new-val"/> with icon
noch
Translated message <br data-l10n-name="icon"/> with no icon
Siehe auch
Fluent-Übersetzungssyntax¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Syntaxfehler in der Übersetzung.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.fluent.syntax.FluentTargetSyntaxCheck- Prüfungskennung:
fluent-target-syntax- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-target-syntax- Markierung zum Ignorieren:
ignore-fluent-target-syntax
In Weblate verwenden Fluent-Zeichenketten die Fluent-Syntax für Verweise und Variablen, aber auch für komplexere Funktionen wie die Definition von Attributen und Selektor-Varianten, einschließlich Pluralformen. Diese Prüfung stellt sicher, dass die in der Übersetzung verwendete Syntax für Fluent gültig ist.
Formatierte Zeichenketten¶
Prüft, ob Zeichenkettenformatierungen in der Quelle und Übersetzung identisch sind. Das Weglassen von Formatzeichenketten in der Übersetzung führt in der Regel zu schwerwiegenden Problemen, daher sollte die Formatierung in Zeichenketten in der Regel mit der Quelle übereinstimmen.
Weblate unterstützt die Überprüfung von Formatzeichenketten in mehreren Sprachen. Die Prüfung wird nicht automatisch aktiviert, sondern nur, wenn eine Zeichenkette entsprechend markiert ist (z. B. c-format für C-Format). Gettext fügt dies automatisch hinzu, aber Sie müssen es wahrscheinlich manuell für andere Dateiformate hinzufügen oder wenn Ihre PO-Dateien nicht von xgettext erzeugt werden.
Die meisten Formatprüfungen erlauben es, Formatzeichenketten für Pluralformen mit einfacher Anzahl wegzulassen. Dies erlaubt Übersetzern, schönere Zeichenketten für diese Fälle zu schreiben (Ein Apfel anstatt %d Apfel). Ausschalten, indem die Markierung strict-format hinzugefügt wird.
Die Markierungen können pro Zeichenkette (siehe Zusätzliche Informationen über Ausgangszeichenketten) oder in einer Komponentenkonfiguration angepasst werden. Die Definition pro Komponente ist einfacher, kann aber zu Fehlalarmen führen, wenn die Zeichenkette nicht als Formatzeichenkette interpretiert wird, doch jene Syntax verwendet.
Hinweis
Für den Fall, dass eine spezifische Formatprüfung in Weblate nicht verfügbar ist, können allgemeine Platzhalter verwendet werden.
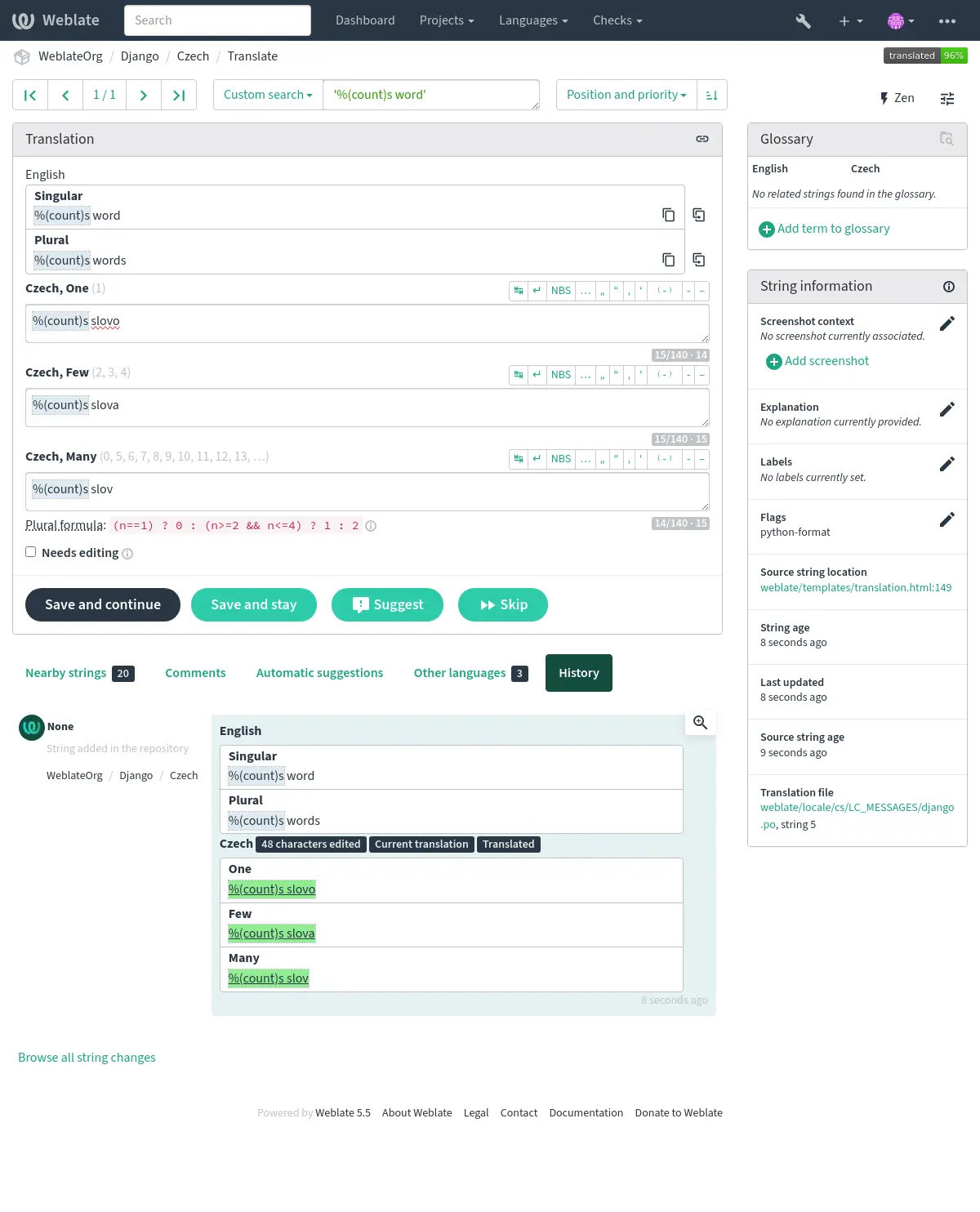
Neben der Überprüfung werden auch die Formatzeichenketten hervorgehoben, um sie leicht in die übersetzten Zeichenketten einzufügen:
AngularJS-Interpolations-Zeichenkette¶
- Zusammenfassung:
AngularJS-Interpolations-Zeichenketten passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.angularjs.AngularJSInterpolationCheck- Prüfungskennung:
angularjs_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
angularjs-format- Markierung zum Ignorieren:
ignore-angularjs-format
- Beispiel für eine benannte Formatzeichenkette:
Your balance is {{amount}} {{ currency }}
Automattic-Komponenten-Formatierung¶
- Zusammenfassung:
Die Platzhalter der Automattic-Komponenten passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.AutomatticComponentsCheck- Prüfungskennung:
automattic_components_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
automattic-components-format- Markierung zum Ignorieren:
ignore-automattic-components-format
- Beispiel für eine einfache Formatzeichenkette:
They bought {{strong}}apples{{/strong}}.
C-Format¶
- Zusammenfassung:
C-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.CFormatCheck- Prüfungskennung:
c_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
c-format- Markierung zum Ignorieren:
ignore-c-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples- Beispiel für eine Zeichenkette im Positionsformat:
Your balance is %1$d %2$s
C#-Format¶
- Zusammenfassung:
C#-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.CSharpFormatCheck- Prüfungskennung:
c_sharp_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
c-sharp-format,csharp-format- Markierung zum Ignorieren:
ignore-c-sharp-format
- Beispiel für eine Zeichenkette im Positionsformat:
There are {0} apples
Siehe auch
ECMAScript-Buchstabenvorlagen¶
- Zusammenfassung:
ECMAScript-Buchstabenvorlagen passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.ESTemplateLiteralsCheck- Prüfungskennung:
es_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
es-format- Markierung zum Ignorieren:
ignore-es-format
- Beispiel für Interpolation:
There are ${number} apples
Siehe auch
i18next-Interpolation¶
Added in version 4.0.
- Zusammenfassung:
Die i18next-Interpolation passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.I18NextInterpolationCheck- Prüfungskennung:
i18next_interpolation- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
i18next-interpolation- Markierung zum Ignorieren:
ignore-i18next-interpolation
- Beispiel für Interpolation:
There are {{number}} apples- Beispiel für Verschachtelung:
There are $t(number) apples
Siehe auch
ICU MessageFormat¶
Added in version 4.9.
- Zusammenfassung:
Syntaxfehler und/oder nicht übereinstimmende Platzhalter in ICU-MessageFormat-Zeichenketten.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.icu.ICUMessageFormatCheck- Prüfungskennung:
icu_message_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
icu-message-format- Markierung zum Ignorieren:
ignore-icu-message-format
- Beispiel für Interpolation:
There {number, plural, one {is one apple} other {are # apples}}.
Diese Prüfung unterstützt sowohl reine ICU-MessageFormat-Nachrichten als auch ICU mit einfachen XML-Tags. Das Verhalten dieser Prüfung kann mit icu-flags:* konfiguriert werden, indem man entweder die XML-Unterstützung aktiviert oder bestimmte Unterprüfungen deaktiviert. Die folgende Markierung aktiviert zum Beispiel die XML-Unterstützung und deaktiviert die Validierung von mehreren Teilnachrichten:
icu-message-format, icu-flags:xml:-plural_selectors
|
Aktiviert die Unterstützung für einfache XML-Tags. Standardmäßig werden XML-Tags lose analysiert. Vereinzelte |
|
Aktiviert die Unterstützung für strikte XML-Tags. Alle |
|
Deaktiviert das Hervorheben von Platzhaltern im Editor. |
|
Deaktiviert die Anforderung, dass Unternachrichten einen |
|
Überspringt die Prüfung, ob die Selektoren der Unternachrichten mit der Ausgangszeichenkette übereinstimmen. |
|
Überspringt die Prüfung, ob Platzhaltertypen mit der Ausgangszeichenkette übereinstimmen. |
|
Überspringt die Prüfung, ob Platzhalter vorhanden sind, die in der Ausgangszeichenkette nicht vorhanden waren. |
|
Überspringt die Prüfung, ob Platzhalter fehlen, die in der Ausgangszeichenkette vorhanden waren. |
Wenn strict-xml nicht aktiviert und xml aktiviert ist, kann außerdem die Markierung icu-tag-prefix:PREFIX verwendet werden, um zu verlangen, dass alle XML-Tags mit einer bestimmten Zeichenkette beginnen. Mit der folgenden Markierung können beispielsweise nur XML-Tags abgeglichen werden, die mit <x: beginnen:
icu-message-format, icu-flags:xml, icu-tag-prefix:"x:"
Dies würde <x:link>click here</x:link> entsprechen, aber nicht <strong>this</strong>.
Java-Format¶
- Zusammenfassung:
Java-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.JavaFormatCheck- Prüfungskennung:
java_printf_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
Android-Zeichenketten-Ressourcen, Mobile-Kotlin-Ressourcen, Compose-Multiplatform-Ressourcen
- Markierung zum Aktivieren:
java-printf-format- Markierung zum Ignorieren:
ignore-java-printf-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples- Beispiel für eine Zeichenkette im Positionsformat:
Your balance is %1$d %2$s
Geändert in Version 4.14: Früher wurde dies durch die java-format-Markierung umgeschaltet, dies wurde aus Gründen der Konsistenz mit GNU gettext geändert.
Java-MessageFormat¶
- Zusammenfassung:
Java-MessageFormat-Zeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.JavaMessageFormatCheck- Prüfungskennung:
java_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
auto-java-messageformat,java-format- Automatisches Verhalten bei Markierungen:
auto-java-messageformat: Treat a text as conditional Java MessageFormat, enabling Java-MessageFormat only when the source contains Java MessageFormat placeholders.- Markierung zum Ignorieren:
ignore-java-format
- Beispiel für eine Zeichenkette im Positionsformat:
There are {0} apples
Geändert in Version 4.14: Früher wurde dies durch java-messageformat umgeschaltet, dies wurde aus Gründen der Konsistenz mit GNU gettext geändert.
Mit dieser Prüfung wird sichergestellt, dass die Formatzeichenkette für die Java-MessageFormat-Klasse gültig ist. Neben der Überprüfung von Formatzeichenketten in geschweiften Klammern werden auch einfache Anführungszeichen überprüft, da sie eine besondere Bedeutung haben. Wenn ein einfaches Anführungszeichen geschrieben wird, sollte es als '' geschrieben werden. Wenn es nicht gepaart ist, wird es als Beginn des Anführungszeichens behandelt und beim Darstellen der Zeichenkette nicht angezeigt.
Siehe auch
JavaScript-Format¶
- Zusammenfassung:
JavaScript-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.JavaScriptFormatCheck- Prüfungskennung:
javascript_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
javascript-format- Markierung zum Ignorieren:
ignore-javascript-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples
Laravel-Format¶
- Zusammenfassung:
Laravel-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.LaravelFormatCheck- Prüfungskennung:
laravel_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
laravel-format- Markierung zum Ignorieren:
ignore-laravel-format
- Beispiel für eine benannte Formatzeichenkette:
The :attribute must be :value
Lua-Format¶
- Zusammenfassung:
Lua-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.LuaFormatCheck- Prüfungskennung:
lua_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
lua-format- Markierung zum Ignorieren:
ignore-lua-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples
Siehe auch
Object-Pascal-Format¶
- Zusammenfassung:
Object-Pascal-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.ObjectPascalFormatCheck- Prüfungskennung:
object_pascal_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
object-pascal-format- Markierung zum Ignorieren:
ignore-object-pascal-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples
Objective-C-Format¶
Added in version 5.17.
- Zusammenfassung:
Objective-C-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.ObjCFormatCheck- Prüfungskennung:
objc_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
objc-format- Markierung zum Ignorieren:
ignore-objc-format
Platzhalter in Prozent¶
Added in version 4.0.
- Zusammenfassung:
Die prozentualen Platzhalter passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PercentPlaceholdersCheck- Prüfungskennung:
percent_placeholders- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
percent-placeholders- Markierung zum Ignorieren:
ignore-percent-placeholders
- Beispiel für eine einfache Formatzeichenkette:
There are %number% apples
Siehe auch
Perl-Brace-Format¶
- Zusammenfassung:
Perl-Brace-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PerlBraceFormatCheck- Prüfungskennung:
perl_brace_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
perl-brace-format- Markierung zum Ignorieren:
ignore-perl-brace-format
- Beispiel für eine benannte Formatzeichenkette:
There are {number} apples
Perl-Format¶
- Zusammenfassung:
Perl-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PerlFormatCheck- Prüfungskennung:
perl_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
perl-format- Markierung zum Ignorieren:
ignore-perl-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples- Beispiel für eine Zeichenkette im Positionsformat:
Your balance is %1$d %2$s
PHP-Format¶
- Zusammenfassung:
PHP-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PHPFormatCheck- Prüfungskennung:
php_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
php-format- Markierung zum Ignorieren:
ignore-php-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples- Beispiel für eine Zeichenkette im Positionsformat:
Your balance is %1$d %2$s
Python-Brace-Format¶
- Zusammenfassung:
Python-Brace-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PythonBraceFormatCheck- Prüfungskennung:
python_brace_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
python-brace-format- Markierung zum Ignorieren:
ignore-python-brace-format
- Einfache Formatzeichenkette:
There are {} apples- Beispiel für eine benannte Formatzeichenkette:
Your balance is {amount} {currency}
Python-Format¶
- Zusammenfassung:
Python-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.PythonFormatCheck- Prüfungskennung:
python_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
python-format- Markierung zum Ignorieren:
ignore-python-format
- Einfache Formatzeichenkette:
There are %d apples- Beispiel für eine benannte Formatzeichenkette:
Your balance is %(amount)d %(currency)s
Qt-Format¶
- Zusammenfassung:
Qt-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.qt.QtFormatCheck- Prüfungskennung:
qt_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
qt-format- Markierung zum Ignorieren:
ignore-qt-format
- Beispiel für eine Zeichenkette im Positionsformat:
There are %1 apples
Siehe auch
Qt-Plural-Format¶
- Zusammenfassung:
Qt-Plural-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.qt.QtPluralCheck- Prüfungskennung:
qt_plural_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
qt-plural-format- Markierung zum Ignorieren:
ignore-qt-plural-format
- Beispiel für eine Zeichenkette im Pluralformat:
There are %Ln apple(s)
Siehe auch
Ruby-Format¶
- Zusammenfassung:
Ruby-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.ruby.RubyFormatCheck- Prüfungskennung:
ruby_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
ruby-format- Markierung zum Ignorieren:
ignore-ruby-format
- Beispiel für eine einfache Formatzeichenkette:
There are %d apples- Beispiel für eine Zeichenkette im Positionsformat:
Your balance is %1$f %2$s- Beispiel für eine benannte Formatzeichenkette:
Your balance is %+.2<amount>f %<currency>s- Beispiel für eine benannte Vorlagenzeichenkette:
Your balance is %{amount} %{currency}
Siehe auch
Scheme-Format¶
- Zusammenfassung:
Scheme-Formatzeichenkette passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.SchemeFormatCheck- Prüfungskennung:
scheme_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
scheme-format- Markierung zum Ignorieren:
ignore-scheme-format
- Beispiel für eine einfache Formatzeichenkette:
There are ~d apples
Vue-I18n-Formatierung¶
- Zusammenfassung:
Die Vue-I18n-Formatierung passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.format.VueFormattingCheck- Prüfungskennung:
vue_format- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
vue-format- Markierung zum Ignorieren:
ignore-vue-format
- Benannte Formatierung:
There are {count} apples- Rails i18n-Formatierung:
There are %{count} apples- Verlinkte lokale Nachrichten:
@:message.dio @:message.the_world!
Ist übersetzt worden¶
- Zusammenfassung:
Diese Zeichenkette wurde in der Vergangenheit übersetzt.
- Bereich:
Alle Zeichenketten
- Prüfklasse:
weblate.checks.consistency.TranslatedCheck- Prüfungskennung:
translated- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-translated
Bedeutet, dass eine Zeichenkette bereits übersetzt wurde. Dies kann passieren, wenn die Übersetzungen im VCS rückgängig gemacht wurden oder anderweitig verloren gegangen sind.
Inkonsistent¶
- Zusammenfassung:
Diese Zeichenkette hat in diesem Projekt mehr als eine Übersetzung oder ist in einigen Komponenten nicht übersetzt.
- Bereich:
Alle Zeichenketten
- Prüfklasse:
weblate.checks.consistency.ConsistencyCheck- Prüfungskennung:
inconsistent- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-inconsistent
Weblate prüft Übersetzungen derselben Zeichenkette für alle Übersetzungen innerhalb eines Projekts, um Ihnen zu helfen, konsistente Übersetzungen zu erhalten.
Die Prüfung schlägt bei abweichenden Übersetzungen dergleichen Zeichenkette innerhalb eines Projekts fehl. Dies kann auch zu Inkonsistenzen in den angezeigten Prüfungen führen. Weitere Übersetzungen dieser Zeichenkette lassen sich auf der Registerkarte Andere Vorkommnisse finden.
Diese Prüfung gilt für alle Komponenten in einem Projekt, bei denen Weitergabe von Übersetzungen erlauben eingeschaltet ist.
Hinweis
Aus Leistungsgründen findet die Qualitätsprüfung möglicherweise nicht alle Inkonsistenzen, so dass die Anzahl der Übereinstimmungen begrenzt ist.
Bemerkung
Diese Prüfung wird auch ausgelöst, wenn die Zeichenkette in einer Komponente übersetzt wird und in einer anderen nicht. Sie kann als schneller Weg genutzt werden, um Zeichenketten, die in einigen Komponenten nicht übersetzt sind, manuell zu behandeln, indem man einfach auf die Schaltfläche Diese Übersetzung verwenden klickt, die in jeder Zeile unter dem Reiter Andere Vorkommnisse angezeigt wird.
Die Erweiterung Automatische Übersetzung kann verwendet werden, um die Übersetzung von neu hinzugefügten und bereits in einer anderen Komponente übersetzten Zeichenketten zu automatisieren.
Inkonsistenter reStructuredText¶
Added in version 5.10.
- Zusammenfassung:
Inkonsistente reStructuredText-Auszeichnung in der übersetzten Nachricht.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.RSTReferencesCheck- Prüfungskennung:
rst-references- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
rst-text- Markierung zum Ignorieren:
ignore-rst-references
reStructuredText-Begriffsreferenzen oder andere Auszeichnungen passen nicht zur Ausgangszeichenkette, die typischen Ursachen für diese Fehler sind:
Nicht übereinstimmende oder fehlende Gravis.
Fehlende Leerzeichen oder Interpunktion um die Referenz. Die Inline-Blöcke von reStructuredText müssen durch Nicht-Wort-Zeichen getrennt werden.
Leerzeichen zwischen Inline-Tag und Gravis.
Der Referenzname wird nicht übersetzt.
Verwenden von Anführungszeichen anstelle von Gravis.
Nicht übereinstimmende Substitutionen oder Fußnotenverweise.
Kashida-Buchstabe verwendet¶
- Zusammenfassung:
Dekorative Kashida-Buchstaben sollten nicht verwendet werden.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.KashidaCheck- Prüfungskennung:
kashida- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-kashida
Die dekorativen Kashida-Buchstaben sollten in der Übersetzung nicht verwendet werden. Diese sind auch als Tatweel bekannt.
Siehe auch
Markdown-Links¶
- Zusammenfassung:
Markdown-Links passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.MarkdownLinkCheck- Prüfungskennung:
md-link- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
md-text- Markierung zum Ignorieren:
ignore-md-link
Markdown-Links passen nicht zur Ausgangszeichenkette.
Siehe auch
Markdown-Referenzen¶
- Zusammenfassung:
Markdown-Link-Referenzen passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.MarkdownRefLinkCheck- Prüfungskennung:
md-reflink- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
md-text- Markierung zum Ignorieren:
ignore-md-reflink
Markdown-Link-Referenzen passen nicht zur Ausgangszeichenkette.
Siehe auch
Markdown-Syntax¶
- Zusammenfassung:
Markdown-Syntax passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.MarkdownSyntaxCheck- Prüfungskennung:
md-syntax- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
md-text- Markierung zum Ignorieren:
ignore-md-syntax
Markdown-Syntax passt nicht zur Ausgangszeichenkette
Siehe auch
Maximale Länge der Übersetzung¶
- Zusammenfassung:
Übersetzung sollte die angegebene Länge nicht überschreiten.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.MaxLengthCheck- Prüfungskennung:
max-length- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
max-length- Markierung zum Ignorieren:
ignore-max-length
Prüft, ob die Übersetzungen eine zulässige Länge haben, damit sie in den verfügbaren Platz passen. Dabei wird nur die Länge der Übersetzungszeichen geprüft.
Im Gegensatz zu den anderen Prüfungen sollte die Markierung als key:value-Paar wie max-length:100 gesetzt werden.
The max-length flag also triggers Länge der Ausgangszeichenkette for source
strings. For English source strings, including English variants, this check
warns when the source uses more than 85% of the configured length to leave room
for translation expansion. For other source languages, the configured
max-length is used directly.
Hinweis
Diese Prüfung bezieht sich auf die Anzahl der Zeichen, was bei der Verwendung von Proportionalschriften zur Textdarstellung nicht unbedingt die beste Metrik ist. Die Prüfung Maximaler Umfang der Übersetzung prüft das tatsächliche Rendering des Textes.
Die Markierung replacements: kann auch nützlich sein, um Platzhalter vor dem Überprüfen der Zeichenkette zu erweitern.
Wenn xml-text ebenfalls verwendet wird, ignoriert die Längenberechnung XML-Tags.
Maximaler Umfang der Übersetzung¶
- Zusammenfassung:
Der gerenderte Text sollte die vorgegebene Größe nicht überschreiten.
- Bereich:
source and translated strings
- Prüfklasse:
weblate.checks.render.MaxSizeCheck- Prüfungskennung:
max-size- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
max-size- Markierung zum Ignorieren:
ignore-max-size
Rendered source or translation text should not exceed given size. It renders the text and checks if it fits into given boundaries. Word wrapping is applied when more than one line is configured.
Für diese Prüfung sind ein oder zwei Parameter erforderlich – die maximale Breite und die maximale Anzahl der Zeilen. Wird die Anzahl der Zeilen nicht angegeben, wird es als einzeiliger Text betrachtet.
Die verwendete Schriftart kann auch durch font-*-Anweisungen konfiguriert werden (siehe Verhalten mit Markierungen anpassen), zum Beispiel besagen die folgenden Übersetzungsmarkierungen, dass der mit der Ubuntu-Schriftgröße 22 gerenderte Text in zwei Zeilen und 500 Pixel passen sollte:
max-size:500:2, font-family:ubuntu, font-size:22
Hinweis
Sie können font-*-Anweisungen in der Komponentenkonfiguration setzen, um die gleiche Schriftart für alle Zeichenketten innerhalb einer Komponente zu konfigurieren. Sie können diese Werte für jede Zeichenkette überschreiben, falls Sie sie pro Zeichenkette anpassen müssen.
Die Markierung replacements: kann auch nützlich sein, um Platzhalter vor dem Überprüfen der Zeichenkette zu erweitern.
Wenn xml-text ebenfalls verwendet wird, ignoriert die Längenberechnung XML-Tags.
Unterschiedliche Menge \n¶
- Zusammenfassung:
Anzahl der \n-Symbole in der Übersetzung passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EscapedNewlineCountingCheck- Prüfungskennung:
escaped_newline- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-escaped-newline
Normalerweise sind maskierte Zeilenumbrüche wichtig für die Formatierung der Programmausgabe. Die Prüfung schlägt fehl, wenn die Anzahl der \n-Symbole in der Übersetzung nicht zur Ausgangszeichenkette passt.
Nicht übereinstimmender Doppelpunkt¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Doppelpunkt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndColonCheck- Prüfungskennung:
end_colon- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-colon
Prüft, ob Doppelpunkte in der Quelle und Übersetzung identisch sind. Das Vorhandensein von Doppelpunkten wird auch für verschiedene Sprachen geprüft, in denen sie nicht vorkommen (Chinesisch oder Japanisch).
Siehe auch
Nicht übereinstimmende Auslassungspunkte¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit Auslassungspunkten.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndEllipsisCheck- Prüfungskennung:
end_ellipsis- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-ellipsis
Prüft, ob nachgestellte Auslassungspunkte in der Quelle und Übersetzung identisch sind. Dies gilt nur für echte Auslassungspunkte (…), nicht für drei Punkte (...).
Auslassungspunkte werden in der Regel schöner als drei Punkte in der Druckschrift dargestellt und hören sich bei Text-to-Speech besser an.
Siehe auch
Nicht übereinstimmendes Ausrufezeichen¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Ausrufezeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndExclamationCheck- Prüfungskennung:
end_exclamation- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-exclamation
Prüft, ob Ausrufezeichen in der Quelle und Übersetzung identisch sind. Das Vorhandensein von Ausrufezeichen wird auch für verschiedene Sprachen geprüft, in denen sie nicht vorkommen (Chinesisch, Japanisch, Koreanisch, Armenisch, Limbu, Birmanisch oder N’Ko).
Siehe auch
Nicht übereinstimmender Punkt¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Punkt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndStopCheck- Prüfungskennung:
end_stop- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-stop
Prüft, ob Punkte in der Quelle und Übersetzung identisch sind. Das Vorhandensein von Punkten wird auch für verschiedene Sprachen geprüft, in denen sie nicht vorkommen (Chinesisch, Japanisch, Devanagari oder Urdu).
Siehe auch
Nicht übereinstimmendes Fragerufzeichen¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Fragerufzeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndInterrobangCheck- Prüfungskennung:
end_interrobang- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-interrobang
Prüft, ob Fragerufzeichen in Quelle und Übersetzung identisch sind. Erlaubt den Tausch zwischen „!?“ und „?!“.
Siehe auch
Nicht übereinstimmendes Fragezeichen¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Fragezeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndQuestionCheck- Prüfungskennung:
end_question- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-question
Prüft, ob Fragezeichen in der Quelle und Übersetzung identisch sind. Das Vorhandensein von Fragezeichen wird auch für verschiedene Sprachen geprüft, in denen sie nicht vorkommen (Armenisch, Arabisch, Chinesisch, Koreanisch, Japanisch, Äthiopisch, Vai oder Koptisch).
Siehe auch
Nicht übereinstimmendes Semikolon¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Semikolon.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndSemicolonCheck- Prüfungskennung:
end_semicolon- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-semicolon
Prüft, ob Semikolons am Satzende in der Quelle und Übersetzung identisch sind.
Siehe auch
Nicht übereinstimmende Zeilenumbrüche¶
- Zusammenfassung:
Anzahl der Zeilenumbrüche in der Übersetzung passt nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.NewLineCountCheck- Prüfungskennung:
newline-count- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-newline-count
Normalerweise sind Zeilenumbrüche wichtig für die Formatierung der Programmausgabe. Die Prüfung schlägt fehl, wenn die Anzahl der Zeilenumbrüche in der Übersetzung nicht zur Ausgangszeichenkette passt.
Fehlende Pluralformen¶
- Zusammenfassung:
Einige Pluralformen sind nicht übersetzt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.consistency.PluralsCheck- Prüfungskennung:
plurals- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-plurals
Prüft, ob alle Pluralformen einer Ausgangszeichenkette übersetzt wurden. Wie die einzelnen Pluralformen verwendet werden, ist in der Definition der Zeichenkette angegeben.
Wenn nicht alle Pluralformen ausgefüllt werden, kann es vorkommen, dass beim Verwenden der Pluralform nichts angezeigt wird.
Mehrere Großbuchstaben¶
Added in version 5.16.
- Zusammenfassung:
Übersetzung enthält Wörter mit mehreren falsch gesetzten Großbuchstaben.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.MultipleCapitalCheck- Prüfungskennung:
multiple_capital- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-multiple-capital
Prüft auf falsche Großschreibung, indem Wörter erkannt werden, die aufeinanderfolgende Großbuchstaben in einem ansonsten kleingeschriebenen oder normal großgeschriebenen Text enthalten (z. B. HEllo oder CAmelCase). Zeichenketten, die in der Ausgangszeichenkette Großbuchstaben enthalten, dürfen auch in der Übersetzung Großbuchstaben enthalten.
Nicht standardisierte Zeichen in Kabyle¶
Added in version 5.12.
- Zusammenfassung:
Verwenden von standardisierten lateinischen Kabyle-Zeichen (z. B. ɣ statt griechischem γ; ɛ statt ε).
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.KabyleCharactersCheck- Prüfungskennung:
kabyle-characters- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-kabyle-characters
Prüft, ob in den kabylischen Übersetzungen die korrekten kabylischen Buchstaben verwendet werden und nicht ähnliche griechische Buchstaben, die oft verwendet wurden, bevor Kabyle-Zeichen in Unicode standardisiert wurden.
Platzhalter¶
Geändert in Version 4.3: Ein regulärer Ausdruck kann als Platzhalter verwendet werden.
Geändert in Version 4.13: Mit der Markierung case-insensitive wird bei Platzhaltern nicht zwischen Groß-/Kleinschreibung unterschieden.
- Zusammenfassung:
In der Übersetzung fehlen einige Platzhalter.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.placeholders.PlaceholderCheck- Prüfungskennung:
placeholders- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
placeholders- Markierung zum Ignorieren:
ignore-placeholders
In der Übersetzung fehlen einige Platzhalter. Diese werden entweder aus der Übersetzungsdatei extrahiert oder manuell mit der placeholders-Markierung definiert, weitere können mit Doppelpunkt getrennt werden, Zeichenketten mit Leerzeichen können in Anführungszeichen gesetzt werden:
placeholders:$URL$:$TARGET$:"some long text"
Falls Sie eine Syntax für Platzhalter haben, können Sie einen regulären Ausdruck verwenden:
placeholders:r"%[^% ]%"
Sie können auch Platzhalter verwenden, bei denen die Groß-/Kleinschreibung nicht berücksichtigt wird:
placeholders:$URL$:$TARGET$,case-insensitive
Siehe auch
Unzulässiges Anfangszeichen¶
Added in version 5.9.
- Zusammenfassung:
Die Zeichenkette beginnt mit einem in CSV unzulässigen Zeichen.
- Bereich:
Glossar-Zeichenketten
- Prüfklasse:
weblate.checks.glossary.ProhibitedInitialCharacterCheck- Prüfungskennung:
prohibited_initial_character- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-prohibited-initial-character
Das Glossar wird oft als CSV weitergegeben, und das Verwenden einiger Zeichen am Anfang wird von vielen Anwendungen eingeschränkt, da diese dazu führen können, dass der Text als Ausdruck ausgewertet wird. Dies betrifft auch Glossare in automatischen Vorschlägen, wo viele Dienste CSV für das Synchronisieren von Glossaren verwenden und solche Zeichenketten ablehnen.
Interpunktionszeichenabstand¶
Geändert in Version 5.10: Diese Prüfung galt früher auch für die bretonische Sprache, war jedoch auf Französisch beschränkt.
- Zusammenfassung:
Es fehlt ein geschütztes Leerzeichen vor doppeltem Interpunktionszeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.PunctuationSpacingCheck- Prüfungskennung:
punctuation_spacing- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-punctuation-spacing
Prüft, ob vor doppelten Interpunktionszeichen (Ausrufezeichen, Fragezeichen, Semikolon und Doppelpunkt) ein geschütztes Leerzeichen steht. Diese Regel wird nur in einigen ausgewählten Sprachen wie Französisch verwendet, wo das Leerzeichen vor doppelten Interpunktionszeichen eine typografische Regel ist.
Regulärer Ausdruck¶
Geändert in Version 5.10: Erweiterte Unterstützung für erweiterte reguläre Ausdrücke einschließlich Unicode-Codepoint-Eigenschaften.
- Zusammenfassung:
Übersetzung stimmt nicht mit regulärem Ausdruck überein.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.placeholders.RegexCheck- Prüfungskennung:
regex- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
regex- Markierung zum Ignorieren:
ignore-regex
Die Übersetzung stimmt nicht mit dem regulärem Ausdruck überein. Der Ausdruck wird entweder aus der Übersetzungsdatei extrahiert oder manuell mit der Markierung regex definiert:
regex:^foo|bar$
Der Abgleich unterstützt auch Unicode-Codepoint-Eigenschaften, einschließlich Skripte und Blöcke:
regex:^[-_\p{L}\p{N}\p{sc=Deva}\p{sc=Thai}]{1,32}$
Hinweis
Verwenden Sie Platzhalter, um fehlende Platzhalter in der Zeichenkette zu erkennen.
Siehe auch
reStructuredText-Syntaxfehler¶
Added in version 5.10.
- Zusammenfassung:
reStructuredText-Syntaxfehler in der Übersetzung.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.RSTSyntaxCheck- Prüfungskennung:
rst-syntax- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
rst-text- Markierung zum Ignorieren:
ignore-rst-syntax
reStructuredText-Syntaxfehler in der Übersetzung. Zu suchende Probleme:
Nicht übereinstimmende schließende/öffnende Tags.
Fehlende Leerzeichen oder Interpunktion um die Referenz. Die Inline-Blöcke von reStructuredText müssen durch Nicht-Wort-Zeichen getrennt werden.
Verwenden von Anführungszeichen anstelle von Gravis.
Wiederverwendete Übersetzung¶
Added in version 4.18.
- Zusammenfassung:
Verschiedene Zeichenketten sind gleich übersetzt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.consistency.ReusedCheck- Prüfungskennung:
reused- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-reused
Prüft, ob dieselbe Übersetzung für verschiedene Ausgangszeichenketten verwendet wird. Solche Übersetzungen können beabsichtigt sein, aber auch Benutzer verwirren.
Sicheres MDX¶
Added in version 2026.7.
- Zusammenfassung:
JSX-Ausdrücke in der Übersetzung passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.mdx.SafeMDXCheck- Prüfungskennung:
safe-mdx- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
safe-mdx- Markierung zum Ignorieren:
ignore-safe-mdx
Identische Pluralformen¶
- Zusammenfassung:
Einige Pluralformen sind identisch übersetzt.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.consistency.SamePluralsCheck- Prüfungskennung:
same-plurals- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-same-plurals
Prüft, ob Pluralformen in der Übersetzung doppelt vorkommen. In den meisten Sprachen müssen diese unterschiedlich sein.
Zeilenumbruch am Anfang¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette beginnen nicht beide mit einem Zeilenumbruch.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.BeginNewlineCheck- Prüfungskennung:
begin_newline- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-begin-newline
Zeilenumbrüche erscheinen normalerweise aus gutem Grund in den Ausgangszeichenketten, denn fehlende oder hinzugefügte Zeilenumbrüche können zu Formatierungsproblemen führen, wenn der übersetzte Text verwendet wird.
Siehe auch
Leerzeichen am Anfang¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette beginnen mit unterschiedlich vielen Leerzeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.BeginSpaceCheck- Prüfungskennung:
begin_space- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-begin-space
Ein Leerzeichen am Anfang einer Zeichenkette wird üblicherweise für Einrückungen in der Darstellung verwendet und sollte deshalb beibehalten werden.
Zeilenumbruch am Ende¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Zeilenumbruch.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndNewlineCheck- Prüfungskennung:
end_newline- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-newline
Zeilenumbrüche erscheinen normalerweise aus gutem Grund in den Ausgangszeichenketten, denn fehlende oder hinzugefügte Zeilenumbrüche können zu Formatierungsproblemen führen, wenn der übersetzte Text verwendet wird.
Siehe auch
Leerzeichen am Ende¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette enden nicht beide mit einem Leerzeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.EndSpaceCheck- Prüfungskennung:
end_space- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-end-space
Prüft, ob nachgestellte Leerzeichen in der Quelle und Übersetzung identisch sind.
Leerzeichen am Ende werden in der Regel verwendet, um benachbarte Elemente voneinander abzugrenzen, so dass ihre Entfernung das Layout beeinträchtigen könnte.
Unveränderte Übersetzung¶
- Zusammenfassung:
Ausgangs- und übersetzte Zeichenkette sind identisch.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.same.SameCheck- Prüfungskennung:
same- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-same
Tritt ein, wenn die Ausgangszeichenketten und die entsprechenden Übersetzungen bis auf eine der Pluralformen identisch sind. Einige Zeichenketten, die in allen Sprachen vorkommen, werden ignoriert, und verschiedene Auszeichnungen werden entfernt. Dadurch wird die Anzahl der Fehlalarme reduziert.
Diese Prüfung kann helfen, irrtümlich nicht übersetzte Zeichenketten zu finden.
Standardmäßig werden bei dieser Prüfung Wörter aus der integrierten Liste der Begriffe von der Prüfung ausgeschlossen. Dies sind Wörter, die häufig nicht übersetzt werden. Dies ist nützlich, um Fehlalarme bei kurzen Zeichenketten zu vermeiden, die nur aus einem einzigen Wort bestehen, das in mehreren Sprachen gleich ist. Diese Liste kann durch Hinzufügen der Markierung strict-same zu einer Zeichenkette oder Komponente deaktiviert werden.
Geändert in Version 4.17: Mit der check-glossary-Markierung (siehe Folgt nicht dem Glossar) werden die nicht übersetzbaren Glossarbegriffe von der Prüfung ausgeschlossen.
Unsicheres HTML¶
- Zusammenfassung:
Die Übersetzung verwendet unsichere HTML-Auszeichnungen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.SafeHTMLCheck- Prüfungskennung:
safe-html- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
HTML-Dateien, Markdown-Dateien, MDX-Dateien, AsciiDoc-Dateien
- Markierung zum Aktivieren:
auto-safe-html,safe-html- Automatisches Verhalten bei Markierungen:
auto-safe-html: Treat a text as conditional HTML, enabling Unsicheres HTML only for plain text or source strings that contain standard HTML markup or valid custom elements. This is useful for extended Markdown variants such as MDX, where angle-bracket syntax may not be HTML.- Markierung zum Ignorieren:
ignore-safe-html
Die Übersetzung verwendet unsichere HTML-Auszeichnung. Diese Prüfung muss mit der safe-html-Markierung aktiviert werden (siehe Verhalten mit Markierungen anpassen). Es gibt auch einen begleitenden Autofixer, der die Auszeichnung automatisch bereinigen kann.
Hinweis
Wenn die Markierung md-text ebenfalls verwendet wird, sind auch Links im Markdown-Stil erlaubt.
Siehe auch
Die HTML-Prüfung wird von der Ammonia-Bibliothek durchgeführt.
URL¶
- Zusammenfassung:
Die Übersetzung enthält keine URL.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.URLCheck- Prüfungskennung:
url- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Markierung zum Aktivieren:
url- Markierung zum Ignorieren:
ignore-url
Die Übersetzung enthält keine URL. Dies wird nur ausgelöst, wenn die Einheit als URL-haltig markiert ist. In diesem Fall muss die Übersetzung eine gültige URL sein.
XML-Auszeichnung¶
- Zusammenfassung:
XML-Tags in der Übersetzung passen nicht zur Ausgangszeichenkette.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.XMLTagsCheck- Prüfungskennung:
xml-tags- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-xml-tags
Das bedeutet normalerweise, dass die Ausgabe unterschiedlich aussieht. In den meisten Fällen ist dies kein erwünschtes Ergebnis einer Änderung der Übersetzung, aber gelegentlich schon.
Prüft, ob XML-Tags in der Quelle und Übersetzung identisch sind.
Die Prüfung wird automatisch für XML-ähnliche Zeichenketten aktiviert. Möglicherweise muss dies mit der xml-text-Markierung in einigen Fällen erzwungen werden.
Bemerkung
Diese Prüfung wird durch die safe-html-Markierung deaktiviert, da die von ihr durchgeführte HTML-Bereinigung Auszeichnungen erzeugen kann, die kein gültiges XML sind.
XML-Syntax¶
- Zusammenfassung:
Die Übersetzung ist kein gültiges XML.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.markup.XMLValidityCheck- Prüfungskennung:
xml-invalid- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-xml-invalid
Die XML-Auszeichnung ist nicht gültig.
Die Prüfung wird automatisch für XML-ähnliche Zeichenketten aktiviert. Möglicherweise muss dies mit der xml-text-Markierung in einigen Fällen erzwungen werden.
Bemerkung
Diese Prüfung wird durch die safe-html-Markierung deaktiviert, da die von ihr durchgeführte HTML-Bereinigung Auszeichnungen erzeugen kann, die kein gültiges XML sind.
Breitenloses Leerzeichen¶
- Zusammenfassung:
Übersetzung enthält zusätzliche breitenlose Leerzeichen.
- Bereich:
Übersetzte Zeichenketten
- Prüfklasse:
weblate.checks.chars.ZeroWidthSpaceCheck- Prüfungskennung:
zero-width-space- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-zero-width-space
Breitenlose Leerzeichen (<U+200B>) werden verwendet, um Nachrichten innerhalb von Wörtern umzubrechen (Wortumbruch).
Da sie normalerweise versehentlich eingefügt werden, wird diese Prüfung ausgelöst, sobald sie in der Übersetzung vorkommen. Einige Programme könnten Probleme haben, wenn dieses Zeichen verwendet wird.
Siehe auch
Quellenüberprüfungen¶
Quellenüberprüfungen können Entwicklern helfen, die Qualität der Ausgangszeichenketten zu verbessern.
Auslassungspunkte¶
- Zusammenfassung:
Die Zeichenkette verwendet drei Punkte
(...)anstelle der Auslassungspunkte(…).- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.source.EllipsisCheck- Prüfungskennung:
ellipsis- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-ellipsis
Dies schlägt fehl, wenn die Zeichenkette drei Punkte enthält (...), obwohl sie Auslassungspunkte verwenden sollte (…).
Die Verwendung von Unicode-Zeichen ist in den meisten Fällen der bessere Ansatz, sieht besser aus und hört sich mit Text-to-Speech vermutlich besser an.
Siehe auch
Inneres HTML der Fluent-Quelle¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Quelle sollte gültiges inneres HTML sein.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.fluent.inner_html.FluentSourceInnerHTMLCheck- Prüfungskennung:
fluent-source-inner-html- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-source-inner-html- Markierung zum Ignorieren:
ignore-fluent-source-inner-html
Fluent wird oft in Kontexten verwendet, in denen der Wert für eine Nachricht (oder einen Begriff) direkt als .innerHTML (statt .textContent) für ein HTML-Element verwendet werden soll. Zum Beispiel, wenn das Fluent-DOM-Paket verwendet wird.
Ziel dieser Prüfung ist es, vorherzusagen, wie der Wert als inneres HTML analysiert wird. Wobei ein HTML5-konformer Parser vorausgesetzt wird, um Fälle abzufangen, in denen es zu einem „unbeabsichtigten“ Verlust der Zeichenkette kommt, ohne zu streng mit technischen Analysefehlern zu sein, die nicht zu einem Verlust der Zeichenkette führen.
Diese Prüfung wird auf den Wert von Fluent-Nachrichten oder -Begriffe angewendet, nicht aber auf deren Attribute. Bei Nachrichten sind die Fluent-Attribute oft nur HTML-Attributwerte, können also beliebige Zeichenketten sein. Bei Begriffen sind die Fluent-Attribute oft Spracheigenschaften, auf die nur in den Selektoren von Fluent-Select-Ausdrücken verwiesen werden kann.
Im Allgemeinen wird von den meisten Fluent-Werten nicht erwartet, dass sie HTML-Auszeichnung enthalten. Daher erwartet diese Prüfung nicht, dass sich Übersetzer und Entwickler um die strikte Vermeidung von irgendwelchen technischen HTML5-Analysefehlern (geschweige denn XHTML-Analysefehlern) kümmern müssen. Stattdessen soll diese Prüfung lediglich eine Warnung ausgeben, wenn sie unbeabsichtigt ein HTML-Tag geöffnet oder eine Zeichenreferenz eingefügt haben.
Darüber hinaus werden für die Fluent-Werte, die absichtlich HTML-Tags oder Zeichenreferenzen enthalten, einige „gute Praktiken“ überprüft, wie z. B. übereinstimmende schließende und endende Tags, gültige Zeichenreferenzen und zitierte Attributwerte. Während die HTML5-Spezifikation technisch gesehen beliebige Tag- und Attributnamen zulässt, beschränkt diese Prüfung sie auf einige grundlegende ASCII-Werte, welche die Standard-HTML5-Element-Tags und -Attribute abdecken sollten, und erlaubt einige benutzerdefinierte Element- oder Attributnamen. Damit soll teilweise sichergestellt werden, dass der Benutzer HTML absichtlich verwendet.
Beispiele:
Wert |
Warnt? |
Grund |
|---|---|---|
|
ja |
|
|
nein |
|
|
ja |
Ein schließendes Tag fehlt. |
|
ja |
|
|
nein |
Benutzerdefiniertes Element-Tag mit einem passenden schließenden Tag. |
|
nein |
|
|
nein |
|
|
ja |
Der Attributwert ist nicht in Anführungszeichen gesetzt. |
|
ja |
Nicht-ASCII-Tag-Name. |
|
ja |
|
|
nein |
Die Zeichenreferenz scheint beabsichtigt zu sein. |
|
ja |
|
|
ja |
Die Zeichenreferenz ist nicht gültig. |
|
ja |
Die Fluent-Variable kann unbeabsichtigt zu einem Tag werden. |
|
ja |
Die Fluent-Variable kann unbeabsichtigt zu einer Zeichenreferenz werden. |
Bemerkung
Diese Prüfung stellt nicht sicher, dass der innere HTML-Code sicher oder bereinigt ist, und ist nicht dazu gedacht, vor böswilligen Versuchen zu schützen, den inneren HTML-Code zu ändern. Außerdem sollte man beachten, dass Fluent-Variablen und -Referenzen zu beliebigen Zeichenfolgen erweitert werden können, also zu beliebigem HTML, wenn sie nicht maskiert werden. Als Ausnahme wird ein <- oder &-Zeichen vor einer Fluent-Referenz diese Prüfung auslösen, da auch ein maskierter Wert zu unerwarteten Ergebnissen führen könnte.
Bemerkung
Das Fluent-DOM-Paket hat weitere Einschränkungen, wie z. B. erlaubte Tags und Attribute, die durch diese Prüfung nicht erzwungen werden.
Siehe auch
Fluent-Quellsyntax¶
Added in version 5.0.
- Zusammenfassung:
Fluent-Syntaxfehler in der Ausgangszeichenkette.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.fluent.syntax.FluentSourceSyntaxCheck- Prüfungskennung:
fluent-source-syntax- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
fluent-source-syntax- Markierung zum Ignorieren:
ignore-fluent-source-syntax
In Weblate verwenden Fluent-Zeichenketten die Fluent-Syntax für Verweise und Variablen, aber auch für komplexere Funktionen wie die Definition von Attributen und Selektor-Varianten, einschließlich Pluralformen. Diese Prüfung stellt sicher, dass die in der Quelle verwendete Syntax auch für Fluent gültig ist.
ICU-MessageFormat-Syntax¶
Added in version 4.9.
- Zusammenfassung:
Syntaxfehler in ICU-MessageFormat-Zeichenketten.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.icu.ICUSourceCheck- Prüfungskennung:
icu_message_format_syntax- Trigger:
Diese Prüfung muss durch eine Markierung aktiviert werden.
- Dateiformate, die diese Prüfung automatisch aktivieren:
- Markierung zum Aktivieren:
icu-message-format- Markierung zum Ignorieren:
ignore-icu-message-format
Siehe auch
Lange nicht übersetzt¶
Added in version 4.1.
- Zusammenfassung:
Die Zeichenkette wurde seit langem nicht übersetzt.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.source.LongUntranslatedCheck- Prüfungskennung:
long_untranslated- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-long-untranslated
Wenn die Zeichenkette lange Zeit nicht übersetzt wurde, kann dies auf ein Problem in der Ausgangszeichenkette hinweisen, welches die Übersetzung erschwert.
Mehrfach fehlgeschlagene Überprüfungen¶
- Zusammenfassung:
In mehreren Sprachen liegen bei den Übersetzungen fehlgeschlagene Qualitätsprüfungen vor.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.source.MultipleFailingCheck- Prüfungskennung:
multiple_failures- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-multiple-failures
Zahlreiche Übersetzungen dieser Zeichenkette haben die Qualitätsprüfung nicht bestanden. Dies ist in der Regel ein Hinweis darauf, dass etwas zur Verbesserung der Ausgangszeichenkette getan werden könnte.
Wenn die Prüfung fehlschlägt, kann das oft an einem fehlenden Punkt am Ende eines Satzes liegen oder an ähnlichen Kleinigkeiten, welche die Übersetzer in der Regel in der Übersetzung korrigieren, während es besser wäre, dies in der Ausgangszeichenkette zu beheben.
Mehrere unbenannte Variablen¶
Added in version 4.1.
- Zusammenfassung:
Die Zeichenkette enthält mehrere unbenannte Variablen, so dass es für Übersetzer unmöglich ist, sie neu zu ordnen.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.format.MultipleUnnamedFormatsCheck- Prüfungskennung:
unnamed_format- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-unnamed-format
Die Zeichenkette enthält mehrere unbenannte Variablen, so dass es für Übersetzer unmöglich ist, sie neu zu ordnen.
Erwägen Sie, stattdessen benannte Variablen zu verwenden, damit die Übersetzer sie neu anordnen können.
Länge der Ausgangszeichenkette¶
- Zusammenfassung:
Die Ausgangszeichenkette ist zu lang, um die konfigurierte maximale Länge einzuhalten.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.source.SourceMaxLengthCheck- Prüfungskennung:
source-max-length- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-source-max-length
Translations often need more room than the source text, especially when the
source language is English. This check helps maintainers find source strings
that are already close to their configured max-length before translators
have to shorten or omit meaning to fit the limit.
For English source strings, including English variants, the check reports
strings using more than 85% of the configured max-length. For other source
languages, it reports source strings longer than the configured
max-length.
This catches source strings that are likely to make translations fail Maximale Länge der Übersetzung, and source strings that already do not fit the declared limit.
Ohne Pluralformen¶
- Zusammenfassung:
Die Zeichenkette wird im Plural verwendet, hat aber keine Pluralformen.
- Bereich:
Ausgangszeichenketten
- Prüfklasse:
weblate.checks.source.OptionalPluralCheck- Prüfungskennung:
optional_plural- Trigger:
Diese Prüfung ist immer aktiviert, kann aber durch eine Markierung ignoriert werden.
- Markierung zum Ignorieren:
ignore-optional-plural
Die Zeichenkette wird als Plural verwendet, benutzt aber keine Pluralformen. Falls Ihr Übersetzungssystem dies unterstützt, sollte die pluralbewusste Variante davon verwendet werden.
Mit Gettext in Python könnte es zum Beispiel so aussehen:
from gettext import ngettext
print(ngettext("Selected %d file", "Selected %d files", files) % files)
Platzhalter in automatischen Vorschlägen¶
Qualitätsprüfungen für Platzhalter geben Aufschluss über aktuelle Platzhalter und können genutzt werden, um automatische Übersetzungsvorschläge zu veranlassen, diese beizubehalten. Die Unterstützung hierfür variiert je nach Dienst und in vielen Fällen gibt es keine Möglichkeit, das Beibehalten von Platzhaltern zu erzwingen.
Siehe auch